この記事は Gunosy Advent Calendar 2017 の3日目の記事です。
昨日の記事はaikizokuさんの現場で役立つAutoLayoutのTips集でした。
はじめに
ニュースパス開発部の koid です。
この記事は、先日 @mathetake が投稿した、下記の記事の続編になります。
tech.gunosy.io
プロジェクトの背景的な部分は、上記の記事を読んでいただきたいのですが、
1. ユーザーはクリックするたびに社内ではファインマンベクトルと
呼ばせている呼ばれているベクトルがリアルタイムに生成かつ更新される
ちょうど、このファインマンベクトルユーザベクトルを、ユーザが記事をクリックする度に、リアルタイムに更新する部分に関わったので、そのときの話を書きたいと思います。
下のアーキテクチャっぽい図でいうと、ちょうど上半分の話になります。
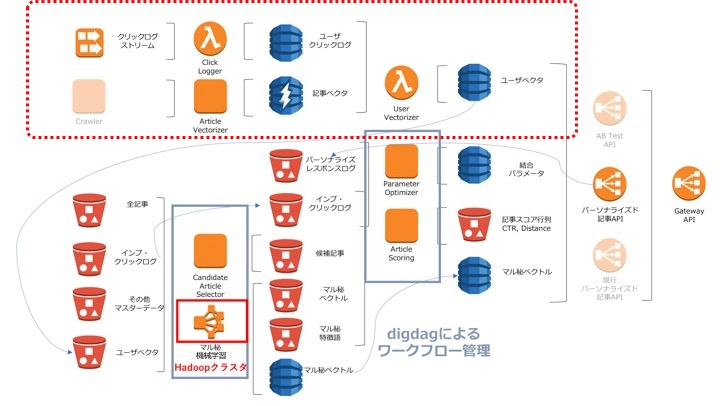
課題と背景
弊社では以前からも様々なプロダクトで、行動履歴ログからベクトルを生成していました。が、ユーザの興味嗜好の変化をより早く反映、新規ユーザの趣味嗜好をより早く反映し、最適な情報を届けるために、旧来のバッチ型アーキテクチャから脱却し、リアルタイム(イベントドリブン)でのユーザベクトル生成を目指しました。
アーキテクチャ概要
ユーザベクトルの生成の流れを簡単にまとめると、下記の流れになります。
- 記事収集と同時に、記事の持つ様々な特徴量を駆使しdenseな記事ベクトルを生成
- ユーザが過去にクリックした記事(およびその際のcontext)のリストを生成
- 上記クリックした記事のベクトルにcontextによって重みを付け、その和を正規化しユーザベクトルを生成

それぞれ、図中のそれっぽい箇所に対応しています。
ベクトル自体の話については前回と同じく大人の事情により余り多くは語れないので、それ以外の部分で語っていきたいと思います。
ユーザの行動履歴(クリックした記事・context)の保持
冒頭でも触れましたが、いわゆるバッチ的に生ログから更新対象ユーザのログを検索し、時系列順にソートして取得するのは、なかなか時間もマシンパワー(すなわち💰)も必要でした。
リアルタイムにベクトル生成をするために、ユーザID一発でGetすることができて、そして揮発しないログストアが欲しく、今回は、DynamoDBのList型を利用することにしました。(下記は雑なイメージです)

DynamoDBには1項目あたり400KBという制限がありますが、クリックした記事と少しのcontextに限定すれば、そこそこの件数が詰められます。1logのサイズからListに詰められる件数を逆算し、list_appendで詰められるだけ詰め(push)、溢れそうになったらremoveで古いlogを追い出していくことで(trim)、ユーザID一発で至近N件のlogをGetできるようになりました。
これを、クリックログが入ってくるKinesis StreamsをTriggerとし、Lambda内でUserID毎にPush/Trimすることで、ほぼ遅延なくDynamoDBに反映することができました。
ユーザの行動履歴の更新に合わせ記事ベクトルを取得
ユーザの行動履歴が更新されるたびに、ユーザベクトルの更新が走ります。ユーザベクトルの更新のためには、最大N件の記事ベクトルを取得(BatchGet)する必要があります。
アーキテクチャの図にもありますが、DynamoDBに入っている記事ベクトルを素直に毎度Getしていると、レイテンシの懸念だけでなく、油田(すなわち💰)も必要になります。
こういうケースの場合、当然前段にキャッシュサーバを挟むと思いますが、ただのGetOrSetならいざしらず、BatchGetOrSetを真面目にコード書くのは面倒です。
下記、弊社エンジニアmosa_siruの資料ですが(良い資料です)、直感的にはわかるもののいざ自分でコードを書き始めてみようとするとなかなか大変です。
そこで DynamoDB用のインメモリキャッシュである、DynamoDB Accelerator (DAX) を利用しました。
DAXを利用するとこんなイメージです(すごい雑なイメージです)

BatchGetOrSetのOrSetの部分は、DAXの中で隠蔽してやってくれるので、そこを意識したコードを書く必要がなく、大変楽です。また、memcachedやredis同様、ローレベルTCPでの通信となるため、非常に低いレイテンシでレスポンスを返してくれます。
これもまた、行動履歴を保存したDynamoDBの更新(DynamoDB Streams)をTriggerにし、Lambda内でユーザベクトル生成と組み合わせることで、最終的にAPIサーバから参照されるDynamoDBにユーザベクトルを反映することができました。
おわりに
現状、新パーソナライズAPIでの計算をどんどん複雑なものにしていきたいという背景もあり、レスポンス速度を維持するために今のところは一旦、ユーザベクトルの生成はあえてリクエストベースにしていません。
しかし、今後新パーソナライズAPIでのロジック(計算量)が固まっていけば、リクエストベースでのユーザベクトル生成にもトライしていけるかなと考えています。
余り多くは語れませんでしたが、詳細が気になるという方、高速なAPIと機械学習アルゴリズムを設計実装する機械学習エンジニア並びにそれを支えるサーバーサイドエンジニアを絶賛募集中です!ご応募ください!
https://hrmos.co/pages/1009778707507720193/jobs/0000063hrmos.co
https://hrmos.co/pages/1009778707507720193/jobs/0000003hrmos.co