こんにちは!スタンディングデスクを導入して快適な開発環境と運動不足の両方を解消できるようになったのではと感じている、広告技術部のUT@mocyutoです。
今回は半年ほどEKSを運用して秒間3万リクエストのトラフィックをさばくほどになりました。 秒間3万は広告システムだと割とあるとは思いますが、kubernetesでも運用できているので紹介しようと思います。 対象のEKSで構築したサービスは広告の配信サーバです。
広告配信サーバの要件として、まず50ms以内にレスポンスを返さなければいけません。 構築したk8sのレスポンスタイムの99パーセンタイルは10msほどで返せています。
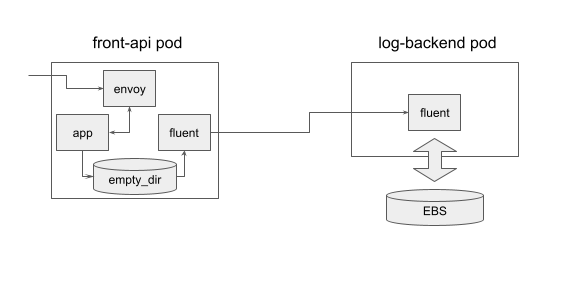
以下は必要最小限のクラスタの構成図です。

API
弊社のサーバサイドはほぼGoで作られているので、例に漏れずGoで作られています。 pod構成はAPI、fluentd、envoyの サイドカーパターン です。 弊社ではプロキシにenvoyを利用するのが一般的になってきました。 これはenvoyを使うことでトラフィックのメトリクスを可視化しやすくなるからです。 envoyを利用するとredisなどの通信も挟むことができますが、envoyのroutingコントロールを手で運用する(手でyamlを書く)のがつらすぎるので、 本サービスではAPIのHTTPエンドポイントのリクエストレスポンスのみにenvoy を適用しています。
また、APIから参照するデータストアはRedisだけになっており、 local cacheとsingleflightを組み合わせて負荷を下げることで安定的にデータを参照できています。
オートスケール
以前spotインスタンスでECSを構成したものを記事で紹介しましたが、今回もfrontのAPIはspotインスタンスで構成しています。
オートスケールには、一般的なcluster autoscaler とHorizontal Pod Autoscalerを使っています。 また、spot運用のため、node termination handlerによる通知でgracefulに停止するようにしています。 cluster autoscalerはpodがpendingになってからスケールするという性質上スケールが遅いので、CPUのターゲットしきい値は60%にすることでトラフィックの急増に耐えています。 また、リクエストの波がピーク時と閑散期で3倍ほどあるので、1pod増えた際のスケール幅を増やすため、インスタンス一台に対してpodが5台くらいになるようにpodサイズを指定しています。
また以下がdeploymentのyamlサンプルです。
kind: Deployment spec: replicas: 1 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 template: spec: containers: - name: front-api volumeMounts: - mountPath: /tmp name: cache-volume readinessProbe: httpGet: path: /ping port: 8081 lifecycle: preStop: exec: command: ["sh", "-c", "sleep 15"] - name: fluent volumeMounts: - mountPath: /tmp name: cache-volume lifecycle: preStop: exec: command: ["/bin/sh", "-c", "while wget -q --spider http://127.0.0.1:8081/ping; do sleep 1; done"] - name: envoy command: ["envoy", "-c", "/etc/envoy/envoy.yaml"] volumeMounts: - mountPath: /etc/envoy name: envoy-config-volume readOnly: true readinessProbe: httpGet: path: /ping port: 8080 lifecycle: preStop: exec: command: ["/bin/sh", "-c", "curl -s -XPOST 127.0.0.1:9901/healthcheck/fail; sleep 10"] volumes: - name: cache-volume emptyDir: {} - name: envoy-config-volume configMap: name: envoy-config
弊社ではenvoyを利用していますが、特にプロキシを挟む用途がなければenvoyのコンテナを使わなくても問題ありません。
ログ処理
ログの転送にはfluentdを利用しており、アプリケーションのpodにはfluentdのサイドカーを利用し、そのログを別のfluent aggregatorのstatefulsetに転送しています。 statefulsetはonDemandを利用しています。 理由としてはaggregatorが頻繁に生き死にすることでログの欠損の可能性が増えることを避けたいのと、 AWSのEBSが同一AZのインスタンスにしかつかず、spotのインスタンスの偏りが発生した際にEBSが紐付かなくなり立ち上がらないなどのケアのためです。
アプリケーションのpodでは、ステートレスにするためflush buffer timeを1秒にしてaggregatorに流しています。 また、上のyamlで記載しているようにappのコンテナより先に死なないようにpreStopでapiの死活を監視し、appコンテナが死んでからfluentのコンテナが落ちるようになっています。 appとfluentコンテナのログの受け渡しはemptyDirを介して渡しています。
aggregatorはbufferをある程度貯めるのでログの欠損をさせないようにstatefulsetにしています。 またトラフィックが多いので、コスト削減のためリクエスト数に応じてシャードによる課金額が増えるKinesis+lambdaでRedisに投入するのではなくfluent pluginを作成して直接Redisに書き込みを行っています。 この変更によってk8sクラスタ内で処理が完結するので、ローカルでのテストが実施しやすくなりました。
また、一部の必須ではないログはアプリケーション側で間引くことでログのS3費と転送料を減らしてコスト削減しています。
CI
CIには現在skaffoldを使っておりimageの作成からkubectl applyまでをskaffoldが担ってくれています。
弊社ではCI-imageを各種作っているので、CircleCIのdeployの設定でも以下だけでdeployできるようになっています。 gunosyのpublic repositoryで作成しているので参考にしていただければと思います。
docker: - image: gunosy/ci-skaffold:1.0.1 steps: - checkout - setup_remote_docker - run: name: docker login command: $(aws ecr get-login --no-include-email) - run: aws eks update-kubeconfig --name << parameters.env_short >>-cluster - run: skaffold run --profile << parameters.env_long >> --label skaffold.dev/run-id="static",skaffold.dev/docker-api-version="static",app.kubernetes.io/managed-by="skaffold",skaffold.dev/tag-policy="static"
現在はskaffoldを利用していますが、canary deployなどを実行する際は、Argo Rolloutsやサービスメッシュなどを導入する必要があります。 が、初手はこれで十分かと思います。
また、kube-systemなどクラスタ全体に関わる設定はterraformで管理し、各アプリ周辺のyamlやDockerfileはアプリのレポジトリで管理しています。
kube-system
ALBを利用しているので alb-ingress-controller を利用しています。 また監視にはdatadogを使っているので、datadog-agent をdaemonsetとして稼働させています。
詰まると言われるDNS周りですが、CoreDNS のHPA運用にしており今のところ特に問題なく稼働しています。 現在広告チームのEKSの同一クラスタに3サービス稼働しており、うち2サービスは秒間1万リクエストを越えています。 それらのリソースが食い合わないように各サービスごとにASGは分けており、 自分たちが管理するデータプレインをそれぞれ分けることで独立性を保っています。
まとめ
以上の構成で5xxはほぼ発生しない安定運用が実現できています。 せっかく書いたのですが、意外に普通の構成のことしか書いていませんでした。 逆に普通の構成でもかなりのリクエストをさばけるということをお伝えすることができたかと思います。 k8s導入の参考になれば幸いです。