広告技術部のUT@mocyutoです。
ついに桜が開花し、やっと春の訪れを感じはじめましたね。 外で気持ちよく飲みたい季節になってきました。
はじめに
今回はEC2上のPythonのバッチをECSのDigdagに置き換えた話をします。
システム概要
今回の移行対象は広告配信に関するバッチ処理を行うシステムでした。
役割としては以下のようなものがあります。
- 広告の配信候補を作成
- 広告の枠情報を作成
- クリックなどのイベントの集計
なぜ移行するのか
大きく分けて以下の2つの理由がありました。
- Celeryをやめたい
- LevelDBをやめたい
Celeryをやめたい
今まではバッチにはPythonのCeleryを使っていました
Celeryはscheduler, worker構成の高い可用性を備えたジョブ管理システムです。 弊社ではジョブのqueueにRedisを使っていましたが、Redisの他にもいろいろな選択肢を持っています。
しかし、以下の理由から移行を考えていました。
- 配信サイドはGoで管理画面はRailsであり、バッチがPythonだったので言語を統一したい
- APIのデータ読み込み元となるLevelDBを撤廃し、MySQLに変更したい
- 一部のバッチが管理画面(Rails)で動いており、配信メンバーがメンテしづらい
- Celeryの運用がつらい
- 複数のworkerが同じtaskを掴むというバグっぽい現象に度々遭遇し、workerを正常に戻すために再起動するというオペレーション必要がった
- taskのリトライがし辛い(タスク管理画面としてflowerを採用していたが、リトライはcurlで実施しなければならない)
などが置き換える理由としてありました。
LevelDBをやめたい
今まではAPIサーバのlocal cacheとしてLevelDBを利用していました。
LevelDBとはKVSで、memcachedやRedisのようにサーバのプロセスとして動くのではなく、ファイルに格納するKVSです。 似たようなプロダクトとしてSQLiteがあります。 しかし、Keyがソートされており、WriteとシーケンシャルなReadが速いという特徴があります。
しかし、以下のようないくつか問題がありました。
- LevelDBは保存データがバイナリのため、バッチが生成した成果物を確認するのにすごい手間がかかる
- PythonのLevelDBクライアントにて0.xバージョンを利用していたが、このライブラリのバージョンを上げるにはAPIサーバとの互換性も担保する必要があり困難だった
そこでMySQLにバッチでデータを生成し、API側はそのデータを数分おきにキャッシュするようにしました。 理由としては、APIサーバ上ではLevelDBには書き込みを行わず、単純なKVSとしてしか利用していないので、MySQLから取得したデータをメモリ上にHashMapとして展開する方法で十分だったからです。
移行計画
アーキテクチャ
アーキテクチャのベースとしては、
を選定していました。
すでにDigdagの運用ノウハウがあったというのが大きかったです。 また、単一のクラスタに複数のバッチを集約しています。 ECS上のクラスタの平均稼働率をあげれば、spotインスタンスが使えるEC2はFargateよりもコスト効率があがるので、ECSを採用しました。
また移行計画が始まった段階では、EKSが東京リージョンに来ていなかったため、EKSは対象外としていました。
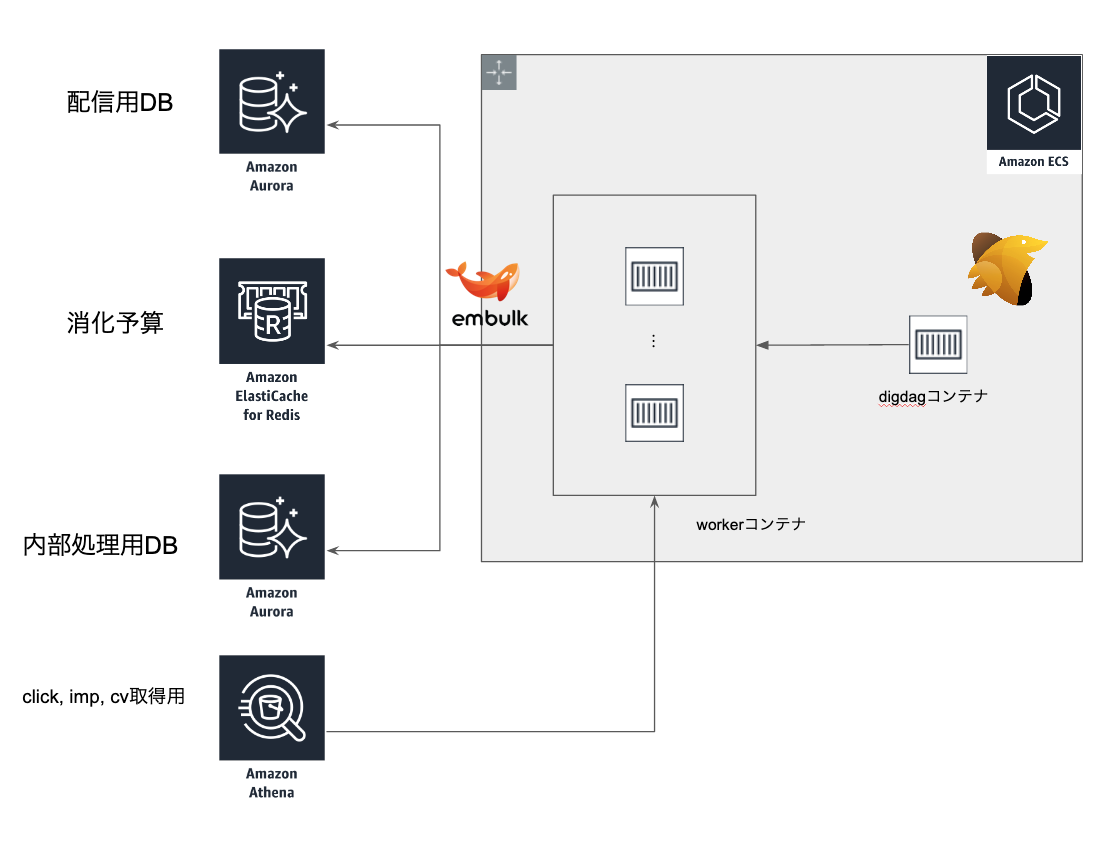
ECS
ECS内は以下の構成です。
- 単一クラスタ内で一連のシステムを動かす。
- masterノードとしてのdigdagコンテナ
- digdagがジョブごとにworkerコンテナを立ち上げる
- embulkに関してもworkerコンテナとして別途立ち上げています。
ECSをdigdagを動かすためのdigdagプラグインを@civitaspo が作っており、OSSとして公開されています。
Athena
今までは管理画面システム(Rails)のバッチがRedshiftのデータを集計し、その結果をCeleryで動いているPythonバッチが取得集計するというフローでした。 しかし、Railsのモデルで管理されているため、普段Railsを開発しない配信サイドのメンバーがメンテしづらいということで、Redshiftと同等のデータがS3に格納されていることもあり、Athenaを使って集計する方針に変更しました。
RedshiftからAthenaへ移行する上でコストの問題を想定していましたが、テストの結果問題ない範囲だったので移行を進めました。
これにより、Railsのモデルで管理されていた集計がSQLになることで、チーム内での汎用化が進みました。
CI/CDフロー
弊社ではGitHubとCircleCIを利用しています。 ECSのデプロイに関しては、hakoというツールを利用しています。
GitHub - eagletmt/hako: Deploy Docker container
docker imageにworkflowを詰めてECRにPushするのではなく、workflowの部分だけS3にアップロードし、Dockerfileにdiffがあった場合のみdocker imageをPushしています。 そして、dockerのentrypointでworkflowをダウンロードするという仕組みにしています。
上記の理由としては、ECRへのimage build + pushは結構遅いので、毎度CIのたびにPushしているとサイクルを回すスピードが遅くてたまらないからです。
Pluginか自前実装か
digdagとembulkを使うと大体がこの2つで実装できてしまいます。 今までPythonバッチ上で実行していた集計などはembulkのpluginなどを利用するとSQLだけでできてしまいます。
そこで、digdagやembulkのpluginを使うかGoで実装したバイナリの実行にするかの基準を決めました。
基本的には実装コストを減らすためにpluginを使う方針にしています。 しかし、pluginを利用するとUnitテストが書けないという問題点があるため、テストが必要な複雑なものはGoで実装して、そうでないものはpluginだけで完結させるという基準にしています。
移行後
よかったこと
- ジョブの実行のライフサイクルとcontainerのライフサイクルが同じなので、containerで動かせることだけに集中すればよい
- コスト効率がいい
- スポットインスタンスを利用することで、オンデマンドインスタンスよりも大きくコストを抑えることができる
- 同一インスタンスで複数PJのジョブを乗せることができるので、インスタンスコストを抑えることができる
- AutoScalingを設定することで、自動でスケールしてくれる
- 実はLevelDBをReadするときにCPU負荷が結構かかっていたらしく、LevelDBをやめたおかげでCPU usageが半分以下になりAPIサーバをかなり減らせた
- SQLなので、スロークエリが出たりバッチに問題が発生しても、SREや配信サイドのメンバーがシュッと確認できるようになった
まとめ
今回ECS上でバッチを組みましたが、移行することで運用負荷が下がり、コストメリットも享受できました。 みなさんもECSの利用を検討してみてはいかがでしょうか?
Container環境でサービス開発を行いたい人、絶賛募集中です!