
こんにちは、koidです。
この記事は Gunosy Advent Calendar 2021 - Adventar の25日目の記事です。
昨日の記事は aitaさんの EKSにJupyterHubを構築した - Gunosy Tech Blog でした。
ドキュメントの更新って面倒だし忘れがち
本題です。 みなさん、Pull Requestのレビュー時に、
ドキュメント・READMEも修正お願いします!
こういったコメントをした/された経験ってありませんか? コメントをする側としても億劫ですし、コメントをされた側としても「宿題やったの?」「今からやろうと思ってたのに!」みたいな幼少期を思い出します*1。
コード変更後のドキュメントのメンテナンス、忘れがちですし、面倒ですよね。 swaggerなりgraphqlなり、schema-firstで開発をしているリポジトリであればSwagger UIやSpectaQL/DociQLなどの恩恵を受けられるのですが…
ドキュメントのメンテナンスを自動化しよう
※お断りとして、この記事での「ドキュメント」とは、UMLなどの高次のものを指すのではなく、コードに密接に連動する「インターフェース仕様」程度の狭義なものとしてお話ししたいと思っています。
本記事の趣旨は、忘れがち・面倒なドキュメントメンテナンスを努力だけでがんばるのではなく、CIによる自動化を進めることにより、下記のContinuous Documentationの原則を達成するとともに、人手でのメンテナンスから解放されようというものです。
- 常に最新である
- 最適な時に作成される
- コードと一致する
以下では、Gunosyにおける取り組みとして、(1) コードからドキュメントを自動生成する試み、(2) 状態からドキュメントを自動生成する試み、の2つをご紹介したいと思います。
コードからドキュメントを自動生成する
コードからドキュメントを自動生成する例の1つとして、社内terraform moduleでの事例を挙げたいと思います。
ツールの利用によるドキュメント生成
先日の、SREチーム茂木さんの記事にあったように、Gunosyではterraformでよく使う組み合わせを、社内terraform moduleとして 整備・運用しています。 社内の色々なチームが使うmoduleなので、使い方のサンプルや、variables/outputs/requirements等々を各moduleのrootにREADMEとして整備しています。
もちろん、運用している中で、variableの追加やデフォルト値の変更などが発生します。以前はこのREADMEを人手で修正していたため、moduleを修正していく中で、記載漏れや修正漏れなどがよく発生していました。 現在は、このREADMEの生成を、 terraform-docsを利用することで自動化しています*2。
terraform-docsでは、 作成したmoduleのvariables/outputs/requirementsおよび、そのdescriptionを読みとり、下記のようなドキュメントを自動的に生成してくれます*3。
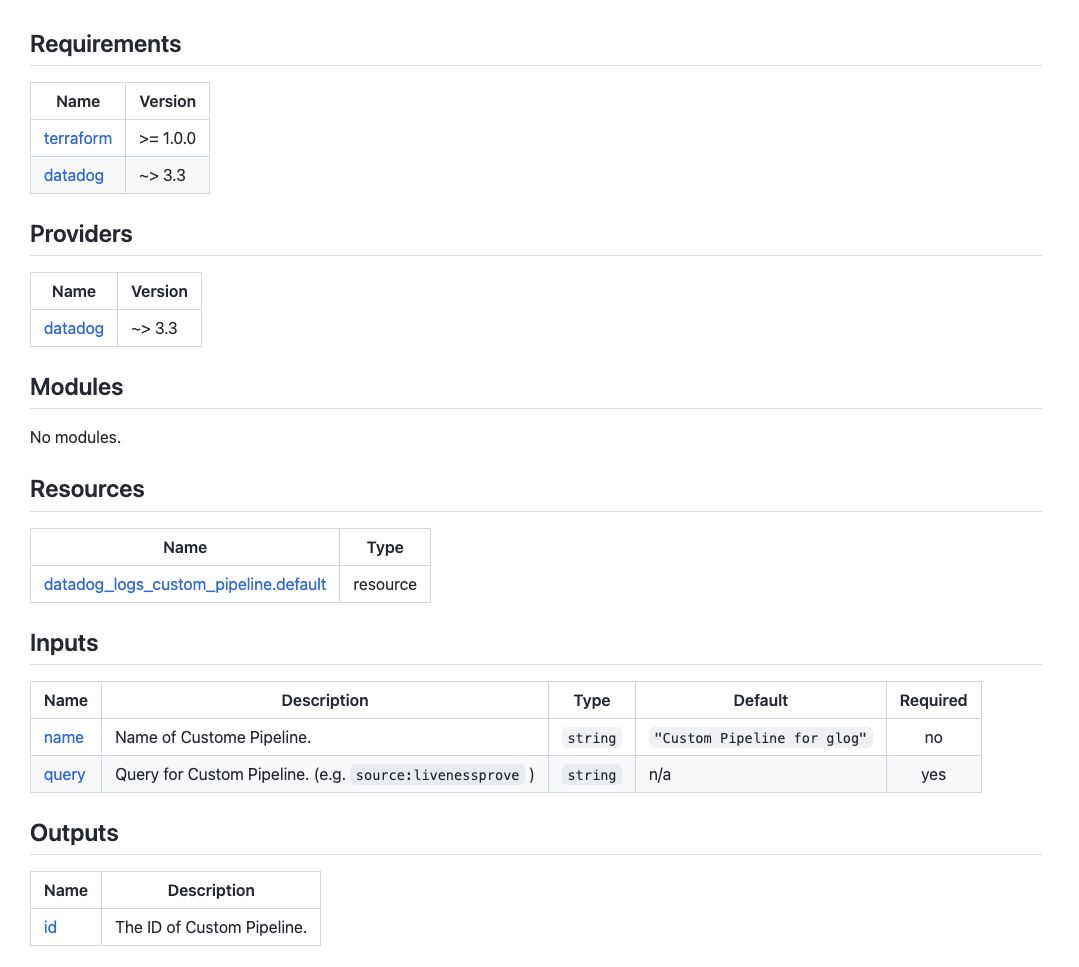
下記のような設定で、BEGIN_TF_DOCS ~ END_TF_DOCSの間がterraform-docsによってメンテナンスされるので、人手で追記したい場合はブロック外に書くことで、人手での記載と自動生成の共存が可能です。
formatter: markdown output: file: README.md mode: inject template: |- [//]: # (BEGIN_TF_DOCS) {{ .Content }} [//]: # (END_TF_DOCS)
CIによるドキュメント生成の自動化
ただツールを導入するだけでは、「修正時に必ずドキュメントが更新される」ことが担保されません(忘れる可能性はあります、そして人は忘れるのです)。
上記のリポジトリでは、必ずドキュメントがコードに追随することを担保するために、Pull-Requestに対してドキュメントの更新PRが生成されるようにCIのワークフローを変更しました。すごく雑ですが、下記のイメージです。

生成されたPRは下記のイメージになります。
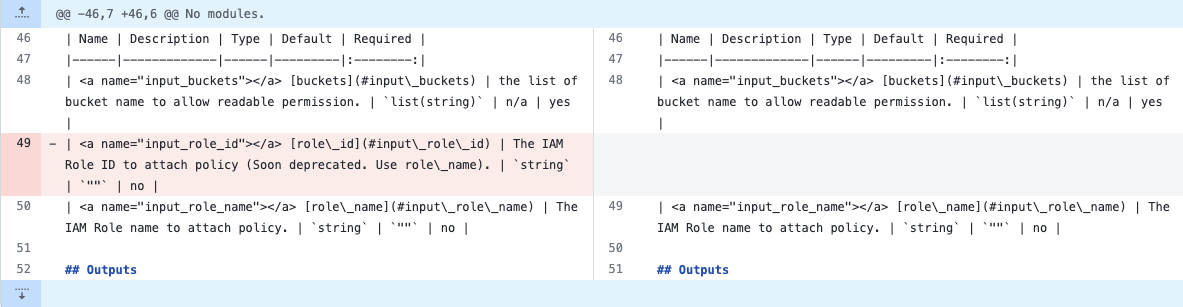
このように CIを利用したドキュメントの更新を行っています*4。
また、リリースタグを切った際のリリースノートの生成も、git-chglog を利用して、CIの中で生成しています。社内moduleをリリースすると、renovateがmoduleを利用している側のリポジトリでバージョン更新PRを生成するようになっており、その際のPRにリリースノートが埋め込まれるようになっています :)
状態からドキュメントを自動生成する
状態からドキュメントを自動生成する例の1つとして、Data Lake/Warehouseでの事例を挙げたいと思います。
ツールの利用によるドキュメント生成
先日の、DR&MLOpsチーム楠さんの記事にあったように、Gunosyではエンジニアに限らず、全社的にRedash等を用いてSQLを書いてデータを分析する人が多くいます。
Data Lake/Warehouseを構築*5している中で、「非エンジニアでも読めるデータのドキュメント」をどう整備するかという課題がありつつも、コードとドキュメントの二重メンテナンスは絶対に破綻するであろう未来が見えていたので、二重メンテナンスが必要ない方法を模索していました。
様々な方法を模索する中で、Data Transformツールであるdbtに、ドキュメントの自動生成機能*6とサービングの機能があることを知り、現在はこれを利用してデータのドキュメントを整備しています*7。
本来、dbtではsource/modelを記述する必要があるのですが、こちらもdbt-codegenというmacroを利用し、データベースのschemaからsource/modelを自動生成*8*9することで、ドキュメントを自動生成することができます。
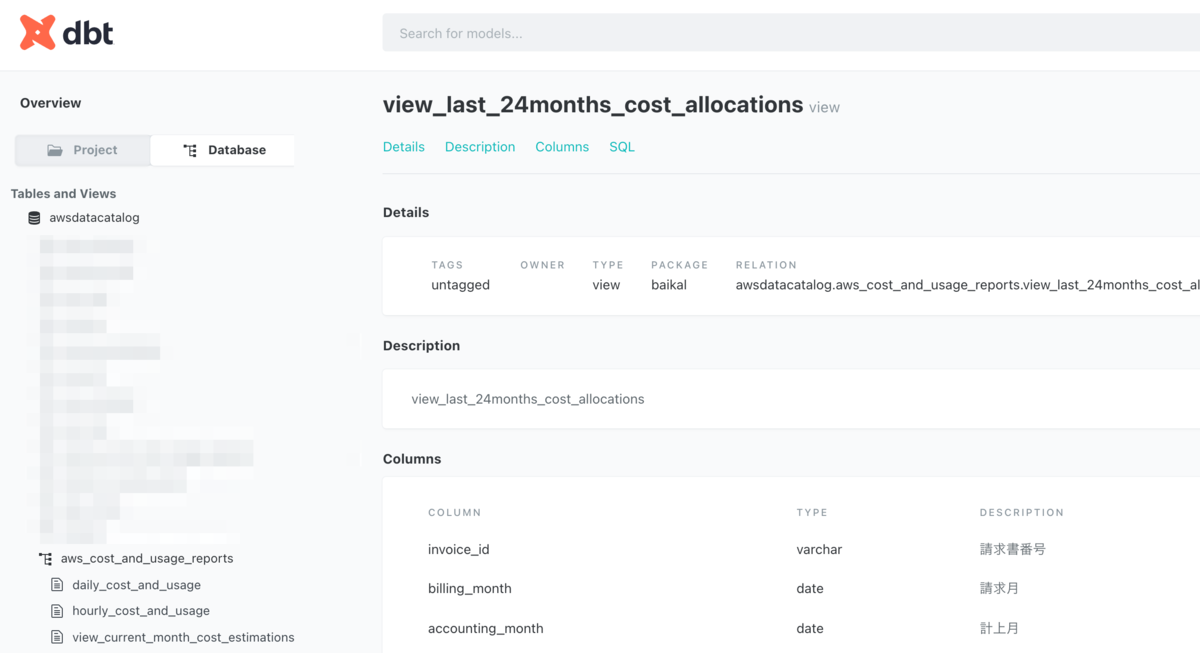
昨今viewの整備をがんばっていたこともあり、別にscriptを用意することにより、viewであればSQLなども一緒に表示していたりします。 まだまだ使いこなせていない部分や、手が及んでない部分もあるのですが、Data Lineage等も表現できるので、使いこなしていきたいです :)
CIによるドキュメント生成の自動化
さきほどの terraform-docs に同じく、ただツールを導入しただけでは、「修正時に必ずドキュメントが更新される」ことが担保されません(再:忘れる可能性はあります、そして人は忘れるのです)。
今回、schemaの管理とdbtの管理が異なるリポジトリだったということもあり、必ずドキュメントがデータベースの更新に追随することを担保するため、データベースの変更(正確にはterraformによりcatalogが更新されたこと)をトリガーとして、dbt側でドキュメントの再作成を行うよう、CIのワークフローを変更しました。
GunosyではCIツールとしてCircleCIを利用しているのですが、異なるリポジトリ間でイベントを発火させるために、APIによるpipeline trigger を利用しています。
commands: circleci_pipeline: parameters: project-slug: type: string data: type: string steps: - run: command: | curl --url https://circleci.com/api/v2/project/<< parameters.project-slug >>/pipeline \ --request POST --header "Circle-Token: ${CIRCLE_API_KEY}" \ --header "content-type: application/json" --data '<< parameters.data >>'
まとめ
人手によるドキュメントとコード両方のメンテナンスは、手間がかかるのはもちろんですが、更新漏れや、書き手によって記述の粒度に違いが出てしまうといった問題が起こりがちです。
しっかりコード側にcommentやdescriptionを書くことを前提*10とし、ドキュメントの生成を可能な限り自動化することで、手間を減らしつつ「コードと一致する」ドキュメントを実現していくことができます。
機械にやってもらえることは機械にやってもらい、我々はもっと楽しい開発をしていきましょう!
*1:人間同士でやると角が立つので、こういうのも全部CIに任せたいですね
*2:goの場合にはgodocがありますね
*3:代わりに、それぞれのdescriptionの記載を徹底しています
*4:Botを作る際にはGitHub CLIが便利です
*5:Gunosyでは、BaikalというAthena/Glueを用いた Data Lake/Warehouseを構築しています
*7:k8sで + ALBでの認証により、社内限定で公開しています
*8:再:代わりに、それぞれのdescriptionの記載を徹底しています
*9:実際のところは、Athenaだと色々困難な道のりがあり、別でscriptを用意しました…公式にadaptorが提供されているものはうまくいくと思います…
*10:descriptionが書かれていないものは、人がレビューで指摘するのではなく、lintやconftestによってCIをfailさせましょう