こんにちは。ML チームの takuji です。
こちらの記事は Gunosy Advent Calendar 2024 の 7 日目の記事です。
本記事では、LLM を使った広告問い合わせ対応の話を書きたいと思います。

なぜやるのか
- 弊社では現在、業務効率化を目指して DX プロジェクトを進めています。各部署の業務課題を特定し、作業時間を出した上で、それぞれの課題を DX 化した際の削減時間を見積もり、インパクトの大きい順に取り組みの優先順位を決定しています。
- この優先順位に基づいて選定された課題の一つが、広告問い合わせ対応です。私はこの課題を担当することになり、LLM を活用して問い合わせ対応を支援するツールの構築に取り組んでいます。これにより、担当者がより創造的な業務に時間を使えるようになることを目指しています。
どのぐらい作業削減になりそうか
- 当初は、一日当たり広告運用担当者(以下、担当者)数名の質問が来ると想定していました。しかし、開発を進める中で関係者へのヒアリングを行った結果、実態が見えてきました。
- 具体的には、以下のような状況が明らかになりました。
- 簡単な質問(Yes / No で回答できてしまう質問)だとそもそも負担ではないこと
- 既存の広告代理店からは依頼系のやり取りが多く、質問が特にない場合があること
- 新規の広告代理店からは質問が来るが、新たに入る代理店の数自体が少ないこと
- この時点で、想定とは乖離していることに気づきましたが、新規の広告代理店には使えそうだったため、作業削減には貢献できると判断しました。
業務にどのように組み込んだのか
- 新しいツールを導入する際は、段階的なアプローチを取ることにしました。完全自動化は初期段階ではリスクが高いと考え、まずは社内の DX アプリケーションのツールの一つとして実装し、試験的な運用からスタートすることにしました。DX アプリケーションは以前から存在していて、複数の部署が利用しています。
- すでに利用実績のある DX アプリケーションに組み込むことで、担当者の準備コスト(VPN 接続の設定など)を最小限に抑えて導入を進めることができました。また、担当者が問題なく使用を開始できるように、今回のツールの利用方法はドキュメントにまとめて共有しました。
- 実際の業務での利用は以下のような流れで行われます。
- 外部のチャットツールなどを経由して代理店から質問が届く
- 担当者は質問を入力して、回答を生成する
- 表示された回答の内容を精査して、適切な判定ステータスを選択する
- 必要であれば回答を手直して、返信内容として使えるレベルの文章にする
- 生成された回答が完全に間違っている時は全て書き換えてもらう
- 補足や要望があったら、コメントフォームに入力する
- 完了ボタンを押して、結果を slack に投下する
- 回答をコピーして、代理店に返信する
どのように回答を生成したのか
- 今回のケースでは、LLM が持っている知識だけでは答えられない質問であったため、RAG を採用しました。RAG とは、LLM の知らない情報を検索によって補完して、回答精度を向上させる技術のことです。
- 情報ソースは以下の3つを利用し、FAQ と PDF 資料は BM25、Zendesk は提供されている API の検索機能を使いました。
- 問い合わせ対応でよくある質問をまとめたスプレッドシート
- Zendesk の記事
- PDF 資料
- 前処理の段階で、PDF を検索容易にするため、テキスト化しました
- 具体的には、PDF 内のテキストを抽出する Python ライブラリと OpenAI の GPT-4V を使いました
- GPT-4V のテキストの誤認識を防ぐため、抽出したテキストをプロンプトに含めました
- アーキテクチャーは 3 つほど検討し、性能的に悪くなく保守コストも低い手法 A を採用しました。評価自体は、代理店質問・弊社回答の事例集を使い、生成した回答の正解/不正解は人手で判定を行いました。
- 検討した手法の特徴は以下の通りです。こちらの記事を参考にしました。
- 手法 A:3 つの情報ソースに検索をかけて関連文書を N 件ずつ取得し、それを元に回答を生成します。情報ソースの優先度(より詳しい内容が載っている情報ソースの方が重要)でプロンプトに差し込む位置を変えて、回答を安定させました。最もシンプルなため、他手法と比べて挙動の制御がしやすいという利点がありました。
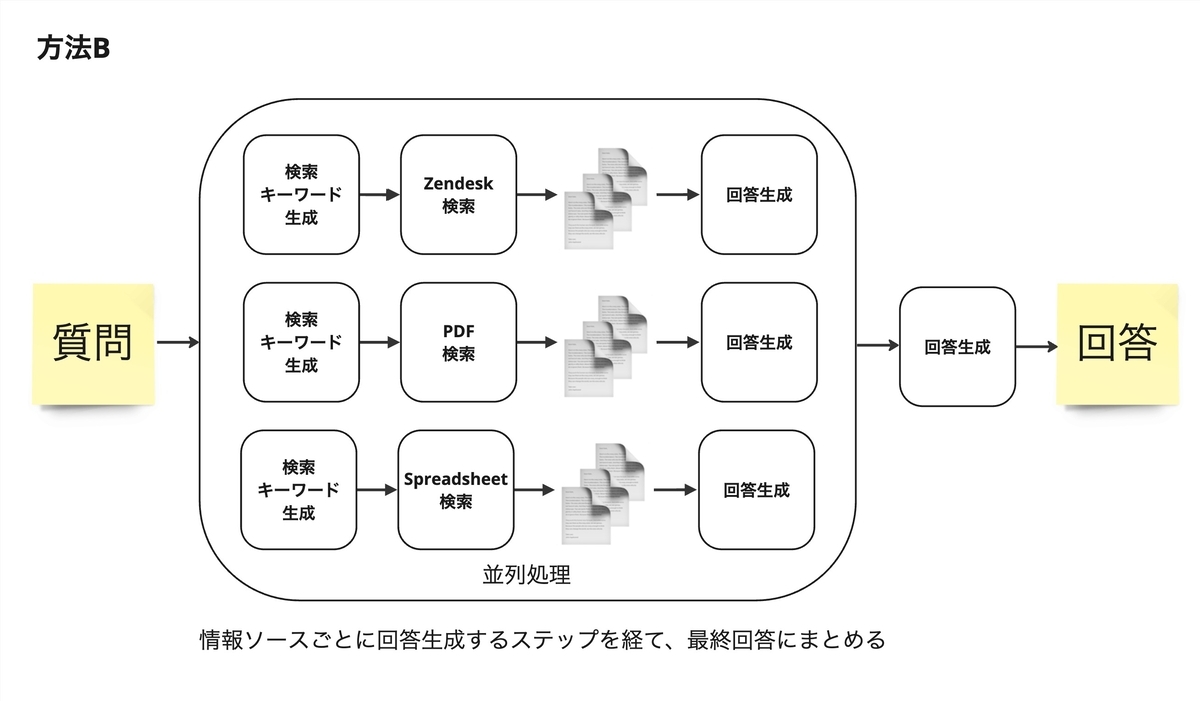
- 手法 B:個別の情報ソースで回答まで一度作り、それを統合して最終回答を生成します。中間地点で回答を生成することで余計な情報を削ぎ落とし、回答精度が上がることを期待しました。
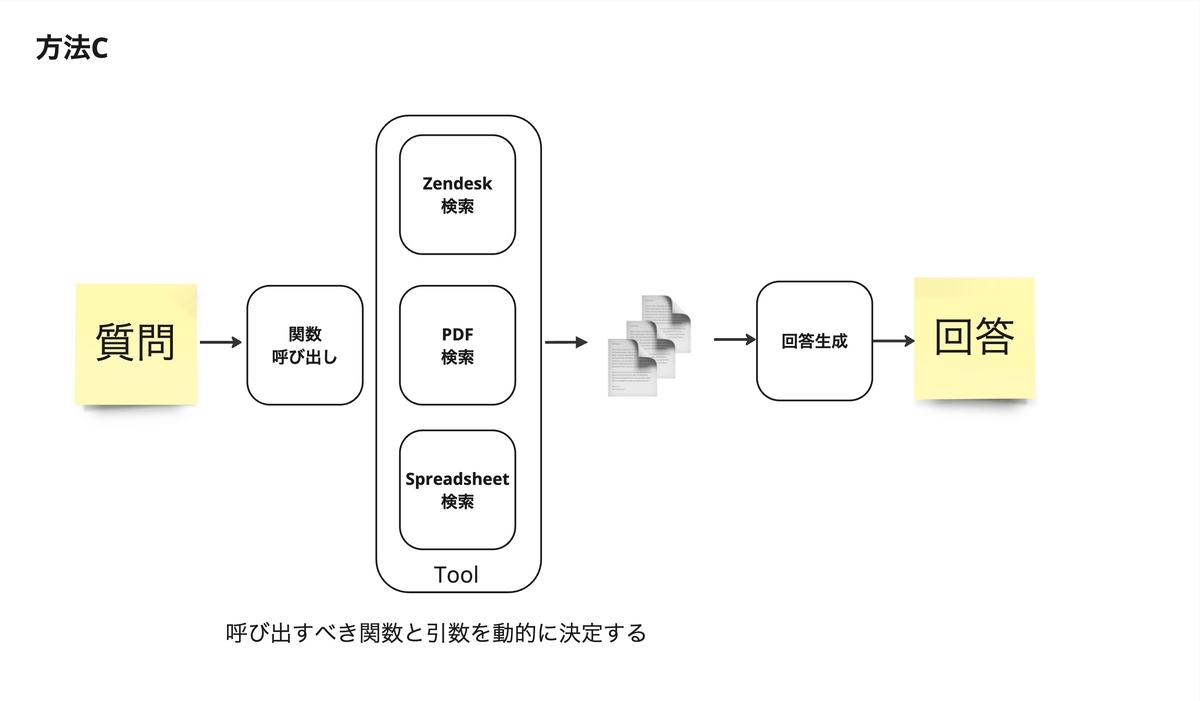
- 手法 C:LLM Agent を使い、必要な情報ソースのみ情報を取得して回答を生成します。質問に無関係な情報ソースは取得しないことで回答精度が上がることを期待しました。
- 評価の結果、手法 C が最も精度が高く、手法 A は少し劣るもののほぼ差がなく、手法 B が最も精度が低いという結果でした。手法 C は Python ライブラリの langchain を使う関係で、デバッグがやや大変で保守運用コストが高い点から、手法 A を採用することにしました。

評価はどうしたのか
- ツールの利用時に得られる判定ステータスを使い、どの程度の精度で回答が生成されているかを評価することにしました。判定ステータスは、「正確、一部正確、不正確、不明」の 4 種類を用意しました。
- 判定基準は以下のように定めました:
- 正確:回答をそのまま利用できる
- 一部正確:軽微な修正で利用できる
- 不正確:大幅な修正が必要、または誤った情報を含む
- 不明:回答できない、または判断できない
- 正確・一部正確の回答が多い場合には、ある程度実用性があると判断できると考えました。一方で、不正確や不明の回答が多い場合は、情報ソースの見直しや回答生成の方法を改善する必要があると判断できます。
- また、各判定結果に対して担当者からコメントを入力できるようにし、どのような点で回答が適切だったか、あるいは不適切だったかを記録できるようにしました。これにより、定性的な評価も可能になりました。
試験運用の結果はどうだったのか
- 試験運用期間は 2024/08/21 ~ 2024/09/13 で、最終的な使用実績は、27 件 / 23 日 = 1.17 件/日 という結果でした。
- 精度面では、正確・一部正確の回答が 70% でしたが、これは実用化に向けてはまだ改善の余地が大きいと考えています。
- 不正確と判定された回答を確認したところ、以下の課題が明らかになりました。
- 伝達ミスがあったためか、SQL 生成・実行を伴う質問がきて、数値の嘘をついていたこと
- 情報ソースの範囲外の質問がきて、回答ができなかったこと(ニーズに合う関連文書がなかったこと)
- 情報ソースとして使った PDF 資料が広告代理店向けの説明を目的としていたため、担当者レベルで必要な詳細な情報が含まれていなかったこと。例えば、CV テストの細かい仕様が不足していたため、実用的な回答を生成することが困難でした
- ここはクリティカルな部分で、単に情報ソースを増やすだけでは解決しない問題でした
振り返り
- LLM を使った業務支援では、インパクトを出すこと・業務に組み込むこと・実績を重ねることが重要だと感じました。
- 最後の「実績を重ねる」点ですが、「何となく使われる」ではなく「価値があるから使われる」に持っていかないと、継続利用は難しいと感じました。
- 継続利用を目指すには、依頼系も捌けるツールに成長させて、問い合わせの主要なケースに対応することだと考えています。
まとめ
- LLM を使った広告問い合わせ対応の話を紹介しました。
- 明日の Gunosy Advent Calendar 2024 では skozawa さんが「データ基盤のコストをAmazon S3 Intelligent-Tieringで削減する」についてお話します。お楽しみに!