こんにちは。新規事業開発室 の igtm です。
こちらの記事は Gunosy Advent Calendar 2024 の 15 日目の記事です。
本記事では、LLM を用いた PDF を元にした回答と、該当箇所のハイライトの話を書きたいと思います。
ウデキキとは
ウデキキとは、用途別にカスタマイズされた「スキル」を通してChatGPTなどの生成AIに文章を生成させることが出来るWebサービスです。
今回はその中の「PDFリサーチアシスタント」というスキルを実装する上で工夫した ①回答の根拠の引用 と②該当箇所のハイライト について説明したいと思います。

① 回答の根拠の引用
LLMにとあるソースの内容に基づいて回答をしてもらう手法の一つとしてRetrieval-Augmented Generation (RAG)があります。 「PDFリサーチアシスタント」スキルにもRAGを使って実装していますが、RAGを使う上で具体的にどの文章を引用してその回答をしたかを出す必要がありました。
具体的には、SystemPromptに回答と共に参考にした文章の引用キー(例えば [PDFのID-チャンクのID] など) を付けるように指示をして、更に質問の入力時にRAGでヒットした文章と引用キーを渡してあげると、出力でLLMが回答の参考にした引用キーが付いて返ってるようになります。
質問
1920年から2020年まで人口はどれだけ増えましたか? Sources: 1-32: 1920年 55,963,053 28,044,185 ... 1-42: 2020 年 10 月1日現在における我が国の人口は1億 2614 万6千人。...
回答
1920年の人口は55,963,053人で、2020年の人口は126,146,099人でした。 したがって、この期間で人口は70,183,046人増加しました [1-32]
②該当箇所のハイライト
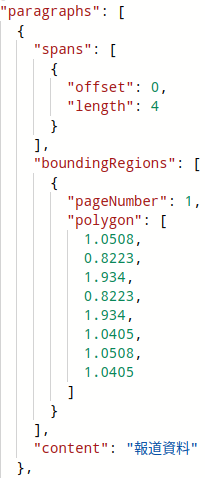
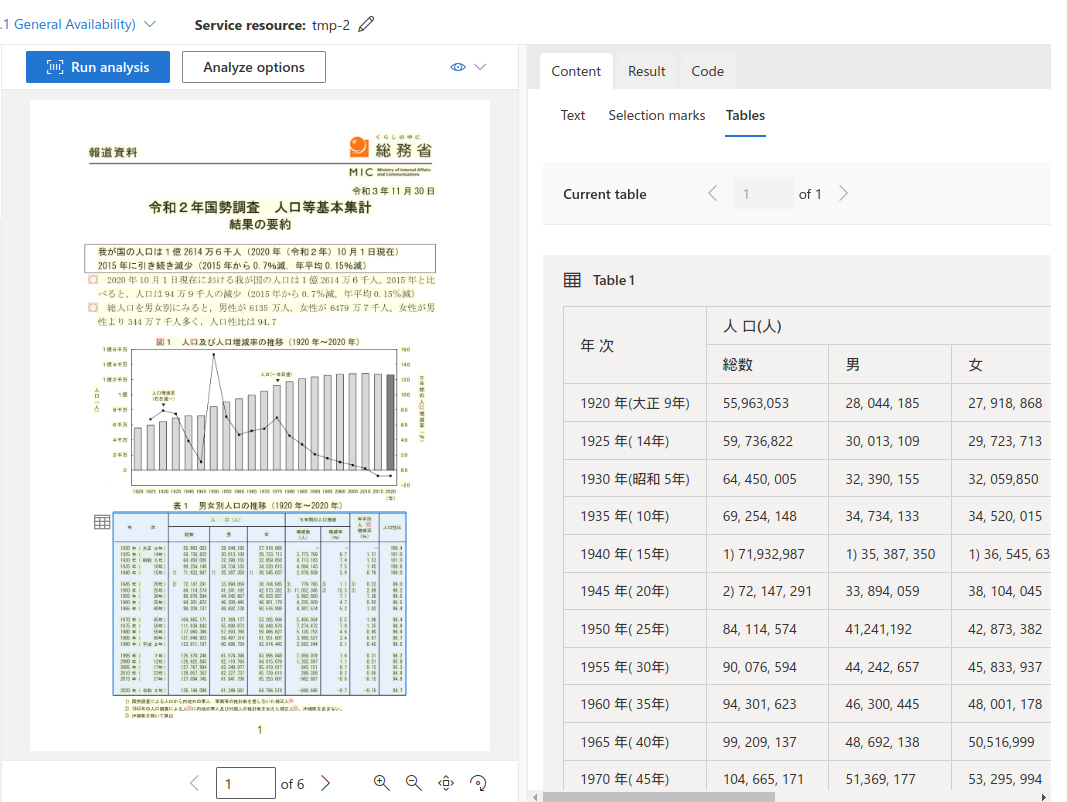
①により、どの部分を参考に回答したかがLLMから出力されるようになりました。 次に、出力された引用キーがPDFのどの箇所かをハイライト表示してユーザーにわかりやすく表示します。 「PDFリサーチアシスタント」スキルでは、PDFの解析に Azure Document Intelligence*1 の layout model を使用しています。
これにより、OCR した文字情報と共に、位置情報(polygon*2)を取得することができます。そして、RAGに利用するチャンクと位置情報を紐付けて利用することで、ハイライトするべき位置情報を算出することができるため、その情報をPDFに渡すことでハイライトができるようにしました。
その他工夫点
- Chunking の手法
単純な文字数によるChunking だと 表が途中で切れてしまって意味のあるチャンクにならない問題があります。そこで MultiVectorRetriever を採用し、表だけを1つのチャンクにすることで正しい結果が返せるようにしました。また表の文字列は数字の羅列のためそのままベクトル化しても質問文にHitしないことが多いため、一度LLMに要約させた文章をEmbeddingにすることでより質問文にHitするように工夫しました(MultiModal RAG)。
まとめ
プロンプトで引用キーを付けるように指示するとしっかりこちらの意図通りに返答してくれるのがかなり驚きました。検証中、様々なモデルで検証しましたが、やはり上位のモデルになればなるほど高い認識力で回答してくれました。ただし100%ではないのでエラー時の処理やモデルやプロンプト別の定量評価などは少し苦労したので今後の課題ではあります。
明日の Gunosy Advent Calendar 2024 では miyagi さんが「QAのバグトラッキングで大切なこと」についてお話します。お楽しみに!
参考文献
*1:https://azure.microsoft.com/ja-jp/products/ai-services/ai-document-intelligence
*2:polygon の単位はインチであることに注意。