こんにちは。ニュースパスのサーバーサイドエンジニアをしているmanoです。
昨年末から、ニュースパスで記事にコメントができるようになりました。 そのコメントデータを、AWS Neptuneを使ってグラフ構造で保持しています。 今回は、その実装・運用について書きたいと思います。
AWS Neptuneって?
AWS Neptuneは、GraphDBが扱えるAWSのフルマネージドサービスです(詳しくはこちら)。
マスター・レプリカ構成のクラスターを作ることができ、レプリカは最大で15まで並べることができます。
GraphDBとのやりとりについて、Neptuneは「グラフトラバーサル言語」であるGremlinとSPARQLをサポートしているので、このいずれかで実装することになります。私はどちらも「なんじゃそりゃ」というところからのスタートだったので、直感的に書き方がしっくりきたGremlinを使って実装することにしました。
なぜ、Neptuneを使おうと思ったのか?
コメント機能を実装すると決まったときは、AuroraかDynamodbで実装する予定だったのですが、弊社SREメンバーから「Neptuneでやっちゃいなよ」という挑むようなセリフをもらい、また社内にNeptuneについての知見を持っている人が誰もいなかったということもあって、おもしろそうだなと思いNeptuneでやることにしました。
一応、いったん期限付きでできるかどうかトライしてみて、感触的に難しそうならAuroraやDynamoDBで実装しようと思っていました。
それが最も大きな理由だったのですが、他には、今後もしかしたら実装するかもしれない、
- コメントに対するコメント(スレッド機能)
- 通常記事以外に対するコメント
などといった機能追加も、データ構造的に容易であるという点にも魅力を感じました。
あとは、簡易的なレコメンド機能の実装も簡単に行える、という利点もあります。
グラフデータの構成について
ニュースパスのコメントデータは、Neptuneでこのような形で保持されています。

上の図について説明していきます。
ちなみにこれ以降の説明にて、こちらで囲われた部分は「label」です。
articleとcommentのvertex(頂点)が、aboutのedge(辺)で結ばれている
(記事<-その記事へのコメント)commentとuserのvertexが、postのedgeで結ばれている
(コメント<-投稿したユーザー)commentとuserのvertexが、likeのedgeで結ばれている
(コメント<-いいねしたユーザー)commentとuserのvertexが、deleteのedgeで結ばれている
(コメント<-削除したユーザー(投稿者のみ可能))commentvertexは、propertyとして下記の情報を保持している。ちなみにvertexは、いくつでもpropertyを持つことができ、個々のpropertyは配列で持つことができる。- 投稿日時
- 本文
like・post・deleteの各edgeは、propertyとしてそれらが結ばれた日時を持っている。なおedgeはvertexとは異なり、propertyは一つしか持つことができない。
このように、GraphDBでは、vertexとedge、そしてそれらのlabelとpropertyを使って、多種類のオブジェクトや、個々のオブジェクト間の関係を簡単に表現することができます。
また、リレーショナルデータベースのようにかっちりとしたスキーマを決める必要もないため、個々のオブジェクトによって自由にpropertyを増減させることも可能です。
例えば、コメントに対してコメントするスレッド機能を実装するとしたら、コメント対象のcommentオブジェクトに対してaboutedgeを伸ばし、スレッド内のcommentvertexと結びつければよいということになります。簡単ですね。
また気になるレスポンスタイムですが、基本的には非常に高速です。
ただ、こちらについては「やってはいけないこと」があります。後述します。
工夫した点
Goで書かれたGremlinドライバーの「gremgo-neptune」
ニュースパスのAPIはすべてGoで実装されているため、Neptuneを使うにはGoで書かれたドライバーを使う必要があります。
いろいろ探したのですが、最終的にgremgo-neptuneが良さそうだなと思い、ただ少し改良を加える必要があったので、forkして修正を加えたものを使っています(こちら)。
改良したのは、主にエラー回りの処理(オリジナルは当初、エラーが発生しても戻り値のerrがnilのままだった・・・!)と、コネクションプールの部分です。
運用中にTokyoリージョンにNeptuneがきたので、オレゴンから移行した
リリース当初、TokyoリージョンにまだNeptuneがなかったため、Oregonリージョンで使っていましたが、レイテンシが結構大きいことに悩まされました。
1つのクエリを発行するだけで、10~100ミリ秒程度かかっていて、Tokyoに早くきてほしいなと思っていたところにきてくれたので、すぐに移行しました。
移行の手順は下記通りです。
- TokyoリージョンにNeptuneクラスターを構築
- コードを修正し、Oregon・TokyoのNeptuneに対しダブルライト
- Oregon Neptuneからスナップショットを取得
- スナップショットからリージョンをまたいだインポートができなかったため、スナップショットからJSONに似た「GraphSON」形式のデータをエクスポート(こちらのツールを使用)
- Tokyo NeptuneにエクスポートしたGraphSONデータをインポート
- ダブルライトをやめ、Tokyoにだけ接続
ちなみにGrapSONデータのインポート時には、すでにTokyo Neptuneにあるvertexやedgeについては無視してくれたので、そこについての考慮は不要でした。
Tokyoに移行してからは、レイテンシは大幅に改善されました。
苦労した点
Gremlin
最も苦労したのは、何と言っても未知の言語である「Gremlin」です。
慣れれば多少は直感的に書くことができるのですが、それまでは本当に苦労しました。
ただ、公式ドキュメントが非常に充実しているので、ここを見ればなんとかなります。
また、「SQLだったらこう書けばいいんだけどなぁ・・・」というようなときが多々あるのですが、その場合はここが参考になります。
データ構造
実装当初、「どのようなデータ構造にするのがGraphDBのベストプラクティスなのか?」などということは全くわからなかったため、手探りで進めていったのですが、まぁ案の定間違っていた部分もいくつかありました。
その中で特に大きかったのは、主に運用上の理由で「削除済みのコメント一覧を出す」ということを定期的に行う必要があるのですが、当初はcommentvertexのproperyにdeleted_atをオプショナルで持たせ、これがあるものが削除済みだというデータ構造になっていました。
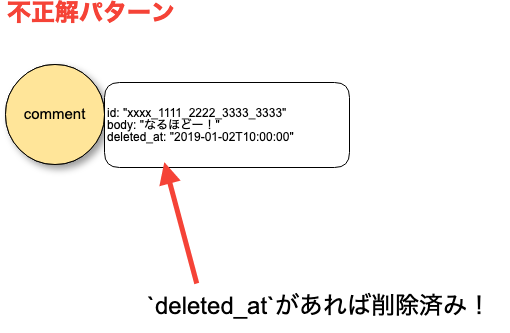 Gremlinクエリ的には、
Gremlinクエリ的には、
g.V().hasLabel("comment").has("deleted_at")
といった感じです。
しかしこれは悪手で、コメントが少ないうちはよかったのですが、データ量が増えるたびにどんどんこのクエリは遅くなっていきました。
そこで、可能な限りpropertyに頼らず、vertexとedgeで表現する形にできないかを考え、下図のように変更したところ、データ量が増えてもクエリの速度が低下するということはなくなりました。
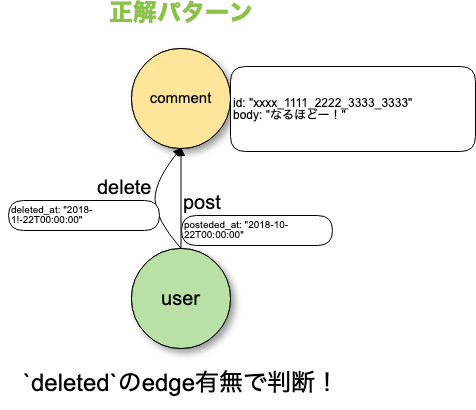
クエリはこんな感じになりました。
g.E().hasLabel("delete").inV().hasLabel("comment")
Gremlinクエリのチューニング
これは今でも試行錯誤が続いている部分も一部ありますが、だいぶましになってきています。
ただ、リリース当初は結構スロークエリに泣かされました。
例えば、コメントデータをCommentIDから抽出するとき、当初はこのように書いていた部分がありました。
g.V().hasLabel("comment").hasId("探したいCommentID")
ただ、このクエリは次のように書いた方が断然早いのです。
g.V("探したいCommentID").hasLabel("comment")
つまり、先にラベルで絞るか、それともvertexのidで絞るか、ということです。
リレーショナルデータベースにて普通に考えたら、先にidで絞る方が当然早いのですが、そこはGraphDBの世界でも同じでした。
Gremlinにできて、Neptuneにできないこと
当記事の執筆時点では、AWS NeptuneのDocker imageというものがないため、ユニットテストなどはGremlin ServerのDocker imageで代用することになります。
ただここで罠となるのが、「通常のGremlin Serverにできて、Neptuneにできない機能の存在」です。
これを知らないと、「あれー!?ユニットテストで通ったのにNeptuneとの疎通がうまくいかない!」ということが起こります。
それについてはこちらにまとまっているので、一読した後に開発されることをおすすめします。
ちなみに、多くは「Neptune側にできないこと」なのですが、その逆もあります。
通常のGremlin Serverでは、たとえlabelの異なるvertexでも同一のvertex idを振ることはできないのですが、Neptuneではlabelさえ異なっていれば同一idを振ることができます。これは便利です。
まとめ
本来ならばコメント機能がリリースされたタイミングでこのような記事を書いておきたかったのですが(昨年末)、当時はまだ不透明な部分があまりにも多く、少し運用してみてから書こうと思いこのタイミングになりました。
また、毎日技術系の記事を見ても、あまりGraphDB関連の記事というのを見かけることがなく、そんな中で私たちのようにがっつりとNeptuneと向かい合っているチームも珍しいのかなと思い、同じように情報の少なさに悩んでいる方々の僅かながらの参考になったらいいなと切に思っています。
ただ、GraphDBってとても楽しいですよ!ぜひ多くの方に遊んでいただきたいと思います。
Gunosyでは、いろんな技術にどんどん挑戦したいと思っているサーバーサイドエンジニアを大募集しています。
https://hrmos.co/pages/1009778707507720193/jobs/0000003hrmos.co