メディア開発部の今村です.
最近はグノシーの社内管理画面のリプレイスをしており, Next.js / Go / GraphQL / MySQLという構成で新しい管理画面を作っています.
開発の途中で, 記事検索機能のページネーションを実装する機会がありました. GraphQLサーバーのページネーションについては, RelayというGraphQLクライアントライブラリが要求しているCursor Connectionsという仕様が有名です. 今回はこの仕様を参考にしたのですが, 読めばすぐに意義や実装方法が分かるというものでもなく, 解説記事を読みながら手探りで実装を進めることになりました.
そこで, この記事では, Cursor Connectionsの仕様, メリットやGoとRDBを使う場合の実装について説明します.
Cursor Connectionsとは
前半は仕様の説明です. 他のページネーション手法との関係を意識した方が見通しが良いので, 単純な手法から順を追って説明していきます.
オフセットページネーション
オフセットページネーションは最も単純な手法です. リクエスト時にoffset, limitという2つの非負整数を渡します. limitはアイテム*1を何件取得するか, offsetは最初の何件を読み飛ばすかを指定するパラメーターです. offset=0, limit=5 であれば1件目から5件目, offset=5, limit=5 であれば6件目から10件目というように, offsetの増減によってページ間を移動できます.
この手法のメリットは実装が簡単なことです. RDBの場合, 次のようにoffset, limitをそのままSQLクエリで使うことができます.
select * from articles order by id limit 5 offset 10;
デメリットは, アイテムの増減に対処できないことです. 例えば, 3つごとに別ページに分かれた6件のアイテム [6, 5, 4], [3, 2, 1] があるとします*2. アイテムが2件増えた場合, [8, 7, 6], [5, 4, 3], [2, 1] となります. ユーザーが1ページ目を表示してから2ページ目に移動するまでの間にこの変化が起こった場合, ユーザーからは [6, 5, 4], [5, 4, 3], ... というようにアイテムが重複して見えてしまいます. 逆に, 途中でアイテムが減った場合, 一部が表示されません.
また, RDBを使う場合, アイテム数が大きくなるにつれパフォーマンスが悪くなるという問題もあります.
カーソルページネーション
オフセットページネーションがアイテムの増減に対処できない理由は, 「上からn件読み飛ばす」という相対的な形でアイテムを指定していたからです.
それに対してカーソルページネーションでは, 「全てのアイテムに割り当てられた一意かつ順序付きのID」, つまりカーソルを使い, 絶対的にアイテムを参照します. アイテムはカーソルについてソートされた状態で提示され, ページの先頭/末尾に対応するカーソルも合わせて分かります. よって, 「末尾アイテムの後のn件」, 「先頭アイテムの前のn件」という形のリクエストを送ることでページ間を移動できます.
この手法では, アイテムの増減が起こっても重複, 抜けは起こりません. また, RDBでは, オフセットページネーションよりも高速な動作が期待できます*3.
デメリットとしては, オフセットページネーションに比べて実装が複雑になること, カーソルとして使えるIDが必要になることが挙げられます.
Cursor Connections
カーソルページネーションは仕様ではなく手法です. GraphQL以外のサーバーでも使えますし, 引数などが明確に定められているわけでもありません.
Cursor Connectionsとは, Relayが要求する, GraphQLサーバー向けのカーソルページネーションの仕様です. 引数やレスポンスの形式などが規定されています.
仕様に準拠したschemaの例を以下に示します.
type Query { search_articles( after: String before: String first: Int last: Int ): ArticleConnection! } type ArticleConnection { edges: [ArticleEdge!]! pageInfo: PageInfo! } type ArticleEdge { node: Article! cursor: String! } type Article { id: Int! } type PageInfo { startCursor: String endCursor: String hasPreviousPage: Boolean! hasNextPage: Boolean! }
search_articlesというクエリでArticle型を扱うのはこの記事特有の部分です. その他の命名規則, 型の作り方が仕様で決まる部分です.
まずはレスポンスの形から見ていきます. Cursor Connectionsに従うレスポンスの型は, XxxxConnection という名前である必要があります. Xxxx の部分はアイテムの型名が入ります. 今回であればArticleです. XxxxConnection型は edges, pageInfoというフィールドを持ちます. pageInfoフィールドは PageInfo 型で, ページの先頭/末尾のアイテムに対応するカーソルや, 前後ページの存在有無を持ちます. edgesは XxxxEdge の配列型です. XxxxEdge型はXxxx型の node フィールドと, そのアイテムに対応するカーソルである cursor フィールドを持ちます. 命名が抽象的なので難しく見えますが, 要は, カーソルやページ情報を含めるためにアイテムやその配列をラップした型で返すということです.
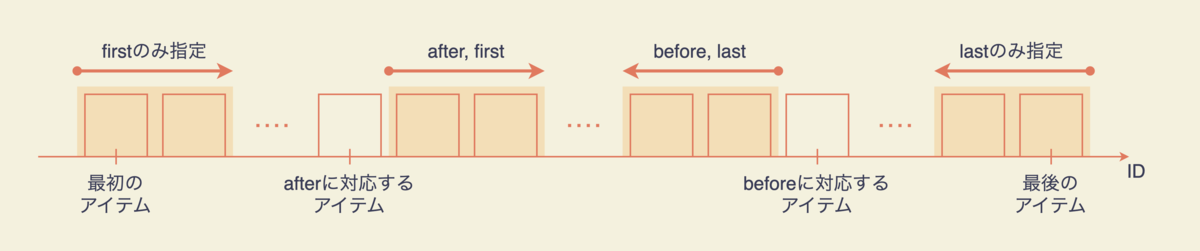
引数は after, before, first, last の4つです. after, beforeはカーソルで, 「このカーソルに対応するアイテムより前/後の」というフィルタリングをするためのパラメーターです. first, lastは, 「最初の/最後のn件」という件数指定をするためのパラメーターです. これら4つは全て任意引数で, 状況に応じて組み合わせて使います. 典型的な組み合わせと, 各組み合わせで得られるアイテムを以下に図示します.
実装
後半は実装についてです. ここではバックエンドの構成と問題設定について説明します.
バックエンドサーバーの言語はGo, DBはMySQLで, GraphQLサーバーライブラリとしてgqlgen, DB層ライブラリとしてsqlxを使っています.
記事が入ったテーブルのschemaと, 対応するGoのstructは以下のようなものとします. 実際の管理画面では, タイトル, 作成日時などによる検索を行っていますが, この記事の興味からは外れるので省略しています.
create table articles ( `id` int not null auto_increment, primary key (`id`) );
type ArticleID = int type Article struct { ID ArticleID }
このテーブルから記事を読み取り, IDの降順でユーザーに提示することが目的です. 説明範囲としては, after, before, first, lastが与えられている状況をスタート, 記事の配列が得られ, 前後ページの存在有無が分かるところまでをゴールとします. それ以外の処理としては, カーソル文字列と記事IDの相互変換, GraphQLのschemaに合わせた構造体の変換などがありますが, 単純なので省略します.
引数のバリデーション
以下のコードでは, 検索パラメーターのバリデーションを行い, SQLクエリに埋め込める形に変換しています.
type searchParams struct { UseAfter bool `db:"use_after"` After ArticleID `db:"id_after"` UseBefore bool `db:"use_before"` Before ArticleID `db:"id_before"` NumRows int `db:"num_rows"` } func NewSearchParams(after *ArticleID, before *ArticleID, first *int, last *int) (searchParams, error) { var sp = searchParams{} sp.UseAfter = (after != nil) sp.UseBefore = (before != nil) useFirst := (first != nil) useLast := (last != nil) if useFirst && !sp.UseAfter && !useLast && !sp.UseBefore { sp.NumRows = *first } else if useFirst && sp.UseAfter && !useLast && !sp.UseBefore { sp.NumRows = *first sp.After = *after } else if useLast && sp.UseBefore && !useFirst && !sp.UseAfter { sp.NumRows = *last sp.Before = *before } else { return searchParams{}, errors.New("{first}, {after, first}, {before, last}のいずれかの組み合わせで指定してください") } return sp, nil }
after, before, first, lastはいずれも任意引数なので, ここではポインタで受け取っています.
パラメータの組み合わせについて, first, lastをどちらも指定しない場合は取得件数が分からないのでエラー, どちらも指定する場合は仕様で非推奨のためエラーとします. それ以外の組み合わせは, Cursor Connectionsの仕様上は全て妥当ですが, 今回の用途では
- firstを指定して1ページ目を取得する
- after, firstを指定して次ページへ進む
- before, lastを指定して前ページへ戻る
の3つのパターンがあれば十分だったため, この3つの場合のみ考慮し, 他はエラーとしています. 組み合わせが妥当な場合, first, lastのどちらかが取得件数(numRows)になります.
after, beforeを値 + それを使うか否かを表すbool変数の形に変換して保持していますが, これはsqlxではオプショナルな変数をそのまま扱うことはできないからです. ページネーションのロジックとは関係ありません.
記事の取得
上記の形に変換したパラメーターを, 以下のSQLクエリに埋め込んで実行し, 記事を取得します.
-- sql/search_articles.sql select id from ( select id from articles where (!(:use_after) or id < :id_after) and (!(:use_before) or id > :id_before) order by 1 %v -- lastが指定されたときのみasc, それ以外はdesc limit :num_rows ) as t order by 1 desc
:use_after のような記法は, sqlxで構造体をクエリに埋め込むためのものです.
where句ではafter, beforeを使って記事のフィルタリングをしています. afterは「指定したIDより後の」記事を選ぶためのパラメーターですが, 今回はIDの降順でユーザーに提示したいため, 「指定したIDよりも小さい」という条件になります. 逆にbeforeは「指定したIDよりも大きい」という条件になります.
オプショナルな変数の対処について, use_after = true なら !use_after = false となり, id < :id_after が評価されて記事のフィルタリングが行われます. use_after = false なら !use_after = true となり, id < :id_after は無視されます. beforeについても同様です.
order by, limitについて, 基本的にはIDの降順で指定件数取得するだけです. before, lastを使う場合のみ, 「beforeより前の(大きい)IDの記事を昇順で指定件数取得し, 降順で表示」とする必要があるので, 上のような形になっています. 他のパラメーターと違い, ソートの順序はGoのfmt.Sprintf関数で埋め込みます. これは, database/sqlライブラリの変数埋め込み機能では構文の変更はできないからです.
上のクエリを使って実際にDBアクセスをするGoのコードは次のようになります.
//go:embed sql/search_articles.sql var querySearchArticles string func SeachArticles(db *sqlx.DB, sp searchParams) ([]Article, error) { as := make([]Article, 0, sp.NumRows) query := fmt.Sprintf(querySearchArticles, sp.order()) query, args, err := sqlx.Named(query, sp) if err != nil { return nil, err } err = db.Select(&as, query, args...) if err != nil { return nil, err } return as, nil }
embedを使ってSQLクエリを変数に入れています. あとはパラメータの埋め込みをして実行するだけです.
次のページの確認
次ページの存在を確認する処理について説明します.
func NextPageExists(db *sqlx.DB, sp searchParams) (bool, error) { if sp.UseBefore { behindRowExists(db, sp) } return additionalRowExists(db, sp) }
searchParamsは検索時に使うものと同じです.
DBに投げるSQLクエリは, {first}, {after, first}, {before, last} のどのパターンかによって分岐します.
{first}, {after, first} の場合は, 記事取得時と同じ条件でnumRows+1件目があるかを確かめれば, 次ページの存在確認ができます.
これを確認するのが additionalRowExists()で, 中身は次のようになっています.
-- sql/additional_row_exists.sql select true from articles where (!(:use_after) or id < :id_after) and (!(:use_before) or id > :id_before) order by 1 %v limit 1 offset :num_rows
//go:embed sql/additional_row_exists.sql var queryAdditionalRowExists string func additionalRowExists(db *sqlx.DB, sp searchParams) (bool, error) { var exists bool query := fmt.Sprintf(queryAdditionalRowExists, sp.order()) query, args, err := sqlx.Named(query, sp) if err != nil { return false, err } err = db.Get(&exists, query, args...) if err != nil && err != sql.ErrNoRows { return false, err } return exists, nil }
クエリはほぼ検索と同じで, limit :num_rowsが limit 1 offset :num_rowsになっており, 記事があった場合はtrueを返します.
{before, last} のパターンでは方法を変える必要があります. このパターンでは「beforeより前の(大きい)IDの記事を昇順で指定件数取得」するので, 同じようにnumRows+1件目を取得すると, 確認できるのはIDが大きい側の記事, つまり前ページの存在になるからです. 次のページを確認するには, 「before以下のIDの記事」があるかを確認する必要があります. これは, where句の不等号条件を反転することで実現できます. これを行うのが behindRowExists()で, 中身は次のようになっています.
-- sql/behind_row_exists.sql select true from articles where (!(:use_after) or id >= :id_after) and (!(:use_before) or id <= :id_before) limit 1
//go:embed sql/behind_row_exists.sql var queryBehindRowExists string func behindRowExists(db *sqlx.DB, sp searchParams) (bool, error) { var exists bool query, args, err := sqlx.Named(queryBehindRowExists, sp) if err != nil { return false, err } err = db.Get(&exists, query, args...) if err != nil && err != sql.ErrNoRows { return false, err } return exists, nil }
前のページの確認
前ページの存在を確認する処理について説明します.
上で述べた通り, {before, last} のパターンでは, numRows+1件目があるかを確認することで前のページの確認ができます.
firstのみのパターンでは, 1ページ目なので前のページはありません.
after, firstのパターンでは, after以上のIDの記事があるかを確認する必要があります. これは, IDについての条件を反転させた behindRowExists()で確認できます.
よって, 前のページの確認は次のようになります.
func PreviousPageExists(db *sqlx.DB, sp searchParams) (bool, error) { if sp.UseAfter { return behindRowExists(db, sp) } if sp.UseBefore { return additionalRowExists(db, sp) } return false, nil }
以上で, 記事の取得, 前後ページの存在確認ができました.
コードは https://github.com/mokeko/go-graphql-pagination で公開しています.
おわりに
この記事では, GraphQLサーバー向けのページネーション仕様であるCursor Connectionsや, GoとRDBを使う場合の実装について説明しました.
実装には課題があり, 1回のGraphQLクエリに対してSQLクエリを3回実行しているのは良くない気がしています*4. また, パターン毎のSQLクエリの書き分けや, パラメーターの埋め込みの部分で記述が多くなってしまったのも改善の余地があります. できるだけ素のSQLを書きたくてsqlxを使ったのですが, 大人しくORMやクエリビルダーを使った方が楽だったかもしれません.
いずれにせよ, Cursor Connectionsを自分で実装する場合はある程度コードが長くなるので, 目的に応じた使い分けが重要だと感じました. 今回の管理画面では, アイテム数が多い部分, アイテムの増減が問題となる部分ではCursor Connectionsを, それ以外の部分ではオフセットページネーションを使っています.
参考文献
-
オフセットページネーション / カーソルページネーション / Cursor Connectionsの関係を説明しています.
https://medium.com/swlh/how-to-implement-cursor-pagination-like-a-pro-513140b65f32
カーソルページネーションのためのSQLクエリやパフォーマンスについて説明しています.
https://www.apollographql.com/blog/graphql/explaining-graphql-connections/
connection, node, edgeといったCursor Connectionsの命名についての説明があります.
https://relay.dev/graphql/connections.htm#
Cursor Connectionsの仕様です.
https://shikatech.hatenablog.com/entry/2021/07/24/090102
同じくGo + RDBの場合の実装を説明している日本語の記事を見つけました. 大まかな実装方針は近いものの, こちらの記事ではORMを使っているのでコードはかなり違ったものになっています.
*1:この記事では, ページネーションの対象となるリストの個々の要素をアイテムと呼びます.
*2:ページのまとまりを表すのに[]を使っています
*3:カーソルとして使うカラムについてのフィルタリングをwhere句で行うので, indexを用意することで読み込むレコードを減らすことができます
*4:additionalRowExists()は, 記事の取得時に1件分多く取得してからGoで件数を確認すれば省略できます. behindRowExists()は一般には省略が難しいと思います. カーソルが連番の整数かつ削除による抜けがないという条件があれば, 記事取得時にafter+1 / before-1を使ってGoで件数を確認するというやり方もありそうです.