こんにちは。 LLM事業部のUTです。
概要
OpenAI による ChatGPT 登場の衝撃から1年ほど経ちましたが、 LLM を活用する企業はものすごく増えました。 OpenAI だけでなく、大手クラウドや Hugging Face などを通して各企業も提供しています。
遊びで使う分にはどの LLM を使うかは適当で良いかと思いますが、プロダクトとして提供する場合利用を想定しているシーンに対して、最適なモデルを選びたいと思うのは必然でしょう。
また LLM を利用してレスポンスを受けるに当たり、最も重要なのがプロンプトです。 様々な研究結果にもある通り、プロンプトの書き方一つで出力結果が大きく変わります。 欲しいアウトプットを出すプロンプトを探すには、プロンプトを複数作り比較する必要があります。
promptfoo の紹介
今回は promptfoo というプロンプトやモデルの比較を行うためのツールを紹介します。
promptfoo は Node.js で作られた LLM のアウトプットの品質を評価する CLI です。 OpenAI や Gemini など複数の LLM に対応していて、テスト関数も多数用意されています。
それでは使い方から紹介していきます。
起動
まずは以下のコマンドでプロジェクトを作成します。
npx promptfoo@latest init
上記を実行すると promptfooconfig.yaml が生成されます。
この生成された yaml が実行に必要な最小限の設定ファイルとなります。
デフォルトでは、 OpenAI がプロバイダとして選択されているので以下のようにシークレットキーと共に実行すると、画像のように評価されます。
OPENAI_API_KEY=sk-abc123 npx promprfoo@latest eval

CLI 上だと確認し辛いかと思うので、以下のコマンドを使ってブラウザから確認してみましょう。
npx promptfoo@latest view
すると、ローカルにキャッシュされた最新の実行結果を以下のようにブラウザで確認することができます。
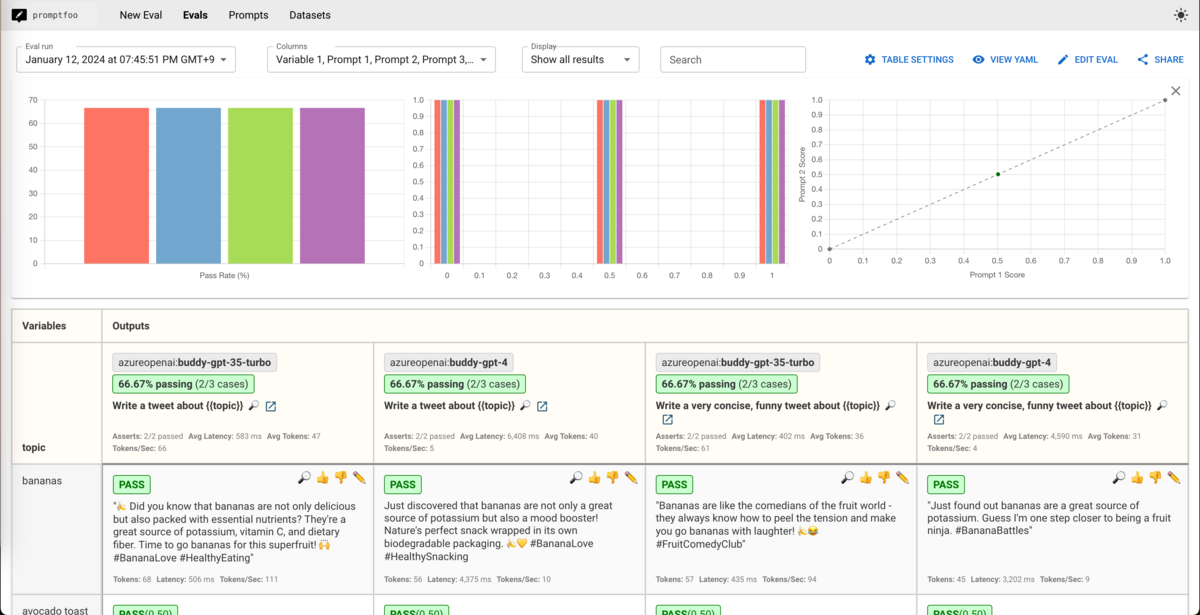
上の図では Azure OpenAI API で実行した結果となっていますが、モデルを変更すれば以下のように Amazon Bedrock や Google の Gemini も混ぜることができます。

上記のように複数モデルを混ぜる場合は以下のように yaml を書きます。
prompts: prompts/azure.yaml: openai_prompt prompts/gemini.yaml: gemini_prompt prompts/claude.yaml: claude_prompt providers: - id: azureopenai:chat:gpt-35-turbo prompts: openai_prompt - id: vertex:gemini-pro prompts: gemini_prompt - id: bedrock:completion:anthropic.claude-v2:1 prompts: claude_prompt tests: - vars: topic: bananas
各モデルでプロンプトのフォーマットが違うため、このような書き方になります。 それぞれ Azure OpenAI では prompts/azure.yaml に、 Gemini では prompts/gemini.yaml にプロンプトを書くと、呼び出されます。
CI での評価
ここまで promptfoo の紹介をしましたが、これをCIで回してプロンプトを変えたときに各モデルの結果が正しいかをチェックしなければなりません。
promptfoo には、テスト関数が多く実装されています。
以下のような LLM の出力結果に対して決定的な関数でテストすることができます。
- contains_all
- regex
また、評価したい LLM のアウトプットに対して、別の LLM との比較を実施する関数もあります。
- similar
- llm-rubric
詳しくは Test assertions | promptfoo に記載されています。
その他、Python や JavaScript を用いて独自の Assertion を導入することも可能です。 弊社では研究開発をもとに、準拠性(プロンプトの指示に従っているか)、可読性(人間が読みやすいか)、正確性(情報の正確性はあるか)等の数十種類の評価アルゴリズムを開発し導入しています。
GitHub Action
promptfoo には GitHub Actions も用意されているので、以下のように記載することですぐに CI でテストを実行させることができます。
GitHub - promptfoo/promptfoo-action
- uses: typpo/promptfoo-action@v1 with: github-token: ${{ secrets.GITHUB_TOKEN }} prompts: 'prompts/**/*.yaml' config: 'prompts/promptfooconfig.yaml' cache-path: ~/.cache/promptfoo env: OPENAI_API_KEY: hoge
この GitHub Actions では、 prompts で指定された入力内のプルリクエストで差分が発生したプロンプトだけ実行するようになっています(最初なぜ動かないのかでハマりました)。 このアクションを使う場合、プルリクエストで差分が発生しているプロンプトだけ実行されるということを意識して CI を回しましょう。
ちなみにデフォルトで promptfoo サーバーに実行結果を送って URL で結果を確認できるようになっています。
また、 no-share オプションを使うことで、実行結果を送らないようにできます。
まとめ
promptfoo 自体、まだまだ発展途上で私もプルリクエストを出したりしています。 LLM の進化が早すぎて、何が陳腐化して何が生き残るかの予想は全く付きませんが、検証のスピードを上げることは開発サイクルを早くすることなので、導入してみてはいかがでしょうか。