本記事は、Gunosy Advent Calendar 2019 17日目の記事です。
昨日の記事は、中村さんによる Pythonしか知らない新卒がGunosyに入るとこうなる - Gunosy Tech Blog でした。
はじめに
はじめましてこんにちは、Gunosy Tech Lab1 Data Reliability & MLOps Group2の大関(@mageyuki)と申します。
弊チームでは、
- Gunosyにおける統合データ基盤
- 集約したデータを活用した機械学習基盤
Gunosyの社是である「数字は神よりも正しい」を根底から支える、重要な2つの基盤の開発運用を行っています。
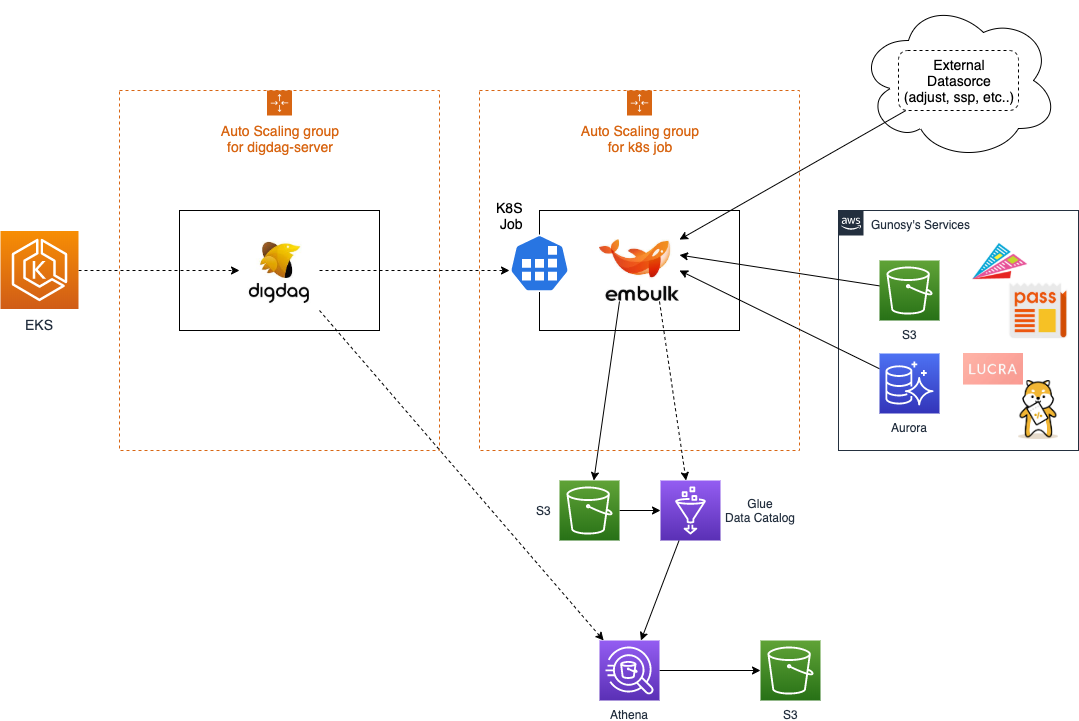
私は主にAWS上に構築したインフラ環境を担当しており、今回は前述の2基盤で共用される、各種バッチ処理を管理するEKS+Digdagで構築したワークフロー基盤にフォーカスして、
- ワークフロー基盤ならではのEKSクラスター運用のポイント(
クラスターが死にかけた事例) - 本環境でEKS on Fargateを軽く検証してみた
の2本立てでお送りします。
ワークフロー基盤について
システム概要
前述の通り、Digdagをベースとしたワークフロー基盤を、EKSクラスター上に構築しています。
EKSクラスターとしての基本構成は非常にオーソドックスで、
- PodのスケーラビリティーはDeployment+HPAで対応
- WorkerNodeのスケーラビリティーはcluster-autoscalerで対応
- PodやNodeの障害に対してはオートヒーリング
- 負荷の増減に対してはオートスケーリング
といった様に、Kubernetesの特色である宣言的な構成管理をフル活用し、様々な変化に対してよろしく対応してくれる「運用の手が掛からない自律制御」をテーマに構築しています。
また、監視環境もよくあるパターンで構成しており、
- kube-state-metricsによるkubernetes内の状態監視
- datadog(+datadog-logs)によるモニタリング、ロギング、ダッシュボード環境
- 各種アラートはSlack通知+PagerDuty
特にアラートは、前述のオートヒーリング/オートスケーリングに対する阻害要因、例えば
- WorkerNode上のkubeletの異常
- CrashLoopBackOffの発生
- CrashLoopBackOffを検知するkube-state-metricsの異常
などを重点的に検知/発報する仕組みを、datadogのmanaged monitor使って構築しています。
ただ一つだけ、世間一般のWebサービス用EKSクラスターと大きく異る点は、社内外の各種データソースに対する多種多様なETL処理を、単発の(Kubernetesの)Jobとして実行しています。
バッチの実行管理とバッチの実行処理を疎結合にするにより、
- 将来的なバッチ処理数の増加
- データソースとの接続方式の追加
などといった構成変更に対して、柔軟に対応できるアーキテクチャーを実現しています。
その日はいきなり訪れた
そんな感じでワークフロー基盤構築も一段落し、接続先のデータソースも増え、同時に社内の各サービスから統合データ基盤への接続も増えていき、クラスターの重要性が日々高まっていった矢先に、事件がおきました。
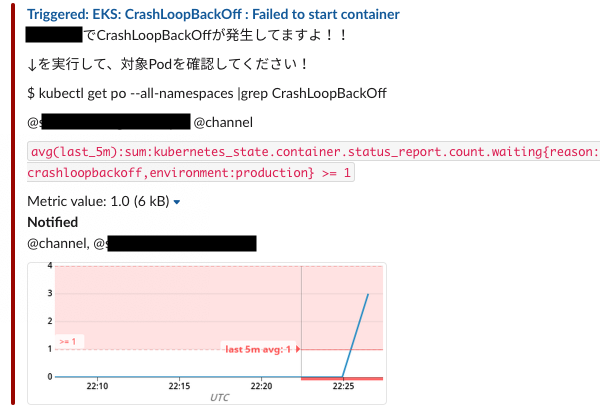
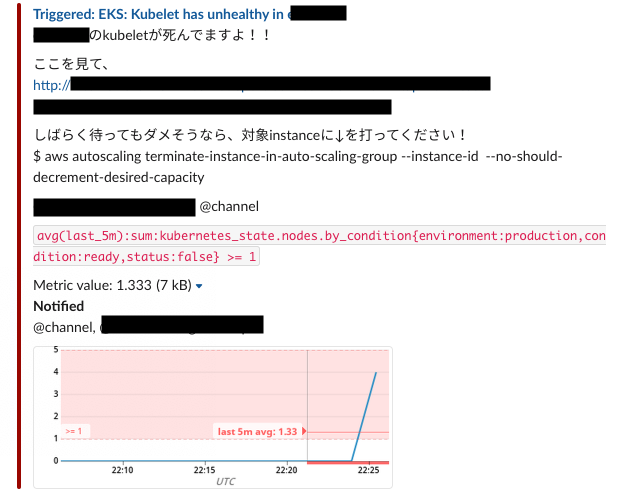
ある日突然、CrashLoopBackOffの発生を告げるアラートが頻発しました。 詳しく調査してみると、以下の事象が確認できました
- cluster-autoscalerやkube-state-metrics、cluster-autoscalerなどいったクラスターの自律制御に重要な管理系Podで、原因不明のエラーによるRestartが多発
- 不特定多数のNode上でKubeletがDown
- DigdagのWorkflowやJobのエラー率向上とスローダウン化
- CrashLoopBackOffまで行かずとも、上記の事象によるPod数の乱高下やKubeletのDownが原因で、Node数も乱高下
- kube-state-metricsから取得できる値(クラスターの正常性を判断するための最重要メトリクス)が不安定(本来ありえない範囲で値が飛び跳ねる)になる
幸いにもこの時点でこれらの現象が発生していたのはステージング環境だけで、本番環境でのバッチ動作とデータ自体に問題は無かったのですが、すでに障害の前兆は本番環境でも現れており、一刻の猶予もありませんでした。
なお、これは後述の原因究明と対策が行われた後に併せて解決したのですが、事件発生前から社内のほかのWebサービス用EKSクラスターに比べて、クラスタ構成や実行Pod数などに大きな差が無いにも関わらず、
- corednsのレスポンスの悪化やRestartの多発
- datadog-agent、cluster-autoscaler、kube-state-metricsといった監視/リソース管理用Podが、異常なまでにリソースを消費する
といった事象が、いま思えば前兆として現れていました。
原因究明
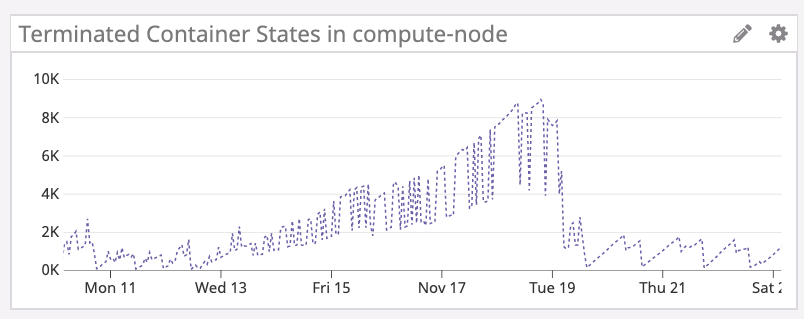
結論から申しますと、JobとJobにより生成されたPodが実行完了後もクラスター内に残り続け、不要なオブジェクトとしてControlPlaneのリソースを圧迫していた事が、クラスター不安定化の原因でした。
JobやPodがクラスタ内に残り続けるということは、
- jobやpodのstatusといった無視できないサイズのデータがetcdに貯まり続け3、
- datadog-agent、cluster-autoscaler、kube-state-metricsといった監視系Podにも「過去に実行されたJob/Pod」としてずっとstateを管理し続け、
- corednsのAレコードにも残り続ける
ということを意味します。
Deploymentにより生成されてReplicasetの世代交代により用済みとなったPodは即座に削除されますが、Jobは明示的に削除を行わない限り残り続けます(Jobを削除すれば、Jobから生成されたPodも削除されます)
Jobから生成されたPodだけは、ControlPlaneにより定期的に自動削除されますが、Podが貯まり続け一回の削除数が多くなるにつれGC実行時にStopTheWorld的な事象が発生し、クラスタが一時不安定になります。
事件発生の数日前に、従来より高頻度に定期実行されるデータ収集用のバッチ処理をデプロイしたことにより、自動削除が追いつかなくなった事が、本事象の顕在化の引き金となっていました。
後述の対策完了後に判明したことですが、最終的に実行済みのPodは約9K、Jobに至っては100K以上蓄積していました😱
対策
対策としては以下の3点が挙げられましたが、
1は、kubectlから取得できるjobのstatusが思ったよりも使いづらく、PodのstatusがSucceededの場合は即座に、Failedの場合はトラブルシュートのために一定期間保持。といった制御が面倒だった。
2は、EKSを始めとしたクラウドKubernetesには現時点未実装で使用できない!!6
といった理由があり、お手軽かつ急を要し、また運用コスト削減のため、3のcleanup-operatorを採用しました
反省点
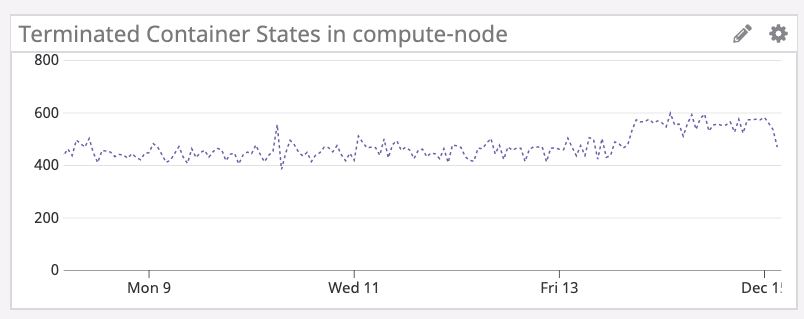
cleanup-operatorによりTerminatedContainer数を削減したことで、EKSクラスターは劇的に安定化しました。
現在では、事件当時より更に多数のJobが実行されています。
反省点を列挙すると、
- Jobのライフサイクル仕様をちゃんと把握していなかった
- EKSというマネージド・サービスを使用していたため、普段目が届かないControlPlane側の仕様や挙動を把握できていなかった
これらを踏まえて、仕様への理解を深めることは当然として、Datadogで取得可能なTerminatedContaierをモニタリングすることで、再発防止を計っています。
まとめ
- EKSのみならずKubernetesでJobを多用する場合は、TerminatedContainer数に注意し、Jobの定期削除を行うこと!!
EKS on Fargateについて
先日のre:Invent2019にてEKS on Fargateが発表され、なんと即日Tokyoリージョンでも利用可能となりました。
ネットでも様々な検証が行われているため詳細は他に譲りますが7、今回はワークフロー基盤用に焦点を当てた検証についてお伝えします。
検証のポイント
Fargateの利点はなんといっても、WorkerNodeのEC2インスタンスの面倒を見なくて済む(=運用コストが激減する)という点です。
本環境では、DigdagServerを始めとしたDeploymentで動作しているPodをFargate化することも魅力ですが、まずはJobをFargate化する事を検討しています。
その理由としては、
- Jobは基本的に短時間(長くて数分、早ければ数十秒)で完了するため、ClusterAutoscalerとの相性が良くない(JobがPending状態となってもスケールアウトが始まる前に次々とJobが完了してしまい、思った様にNode数が増えない)
- Workflowのスケジュール設定上、Jobはだいたい似たような時間に実行され、かつ短時間で完了するため、WorkerNodeのリソースが遊んでいる(特にCPU)
- Fargateなら実行時間単位で課金される。JobのResoucesを上げれば上げるほど早く処理が完了するため、Fargateとの相性が良い。まさに三方良し。
検証内容
FargateProfileを作成し、このようなJobを実行してみました。
このテストJobをデプロイすると3つのPodが起動し、3秒sleepして終了します。 検証結果を動画でまとめました
JobとPodが完了してもオブジェクトが残り続けるのは先刻承知でしたが、なんとNodeまで残り続けるのは予想外でした...
Podと同じ様に、Jobを削除すればNodeも削除されるので定期削除は可能ですが、
- 不要なオブジェクトを、さらに毎時約500もクラスター内に保持し続けるのはちょっとね...(近いうちに1Kに到達する)
- Job完了後もNodeのStatusはReadyのままとなっているので、もしかしたらsubnet内のIPアドレスを専有し続けているのでは...?
ちなみにDashboard上からでも確認できます。どう考えても実際にNodeがいそうな予感...
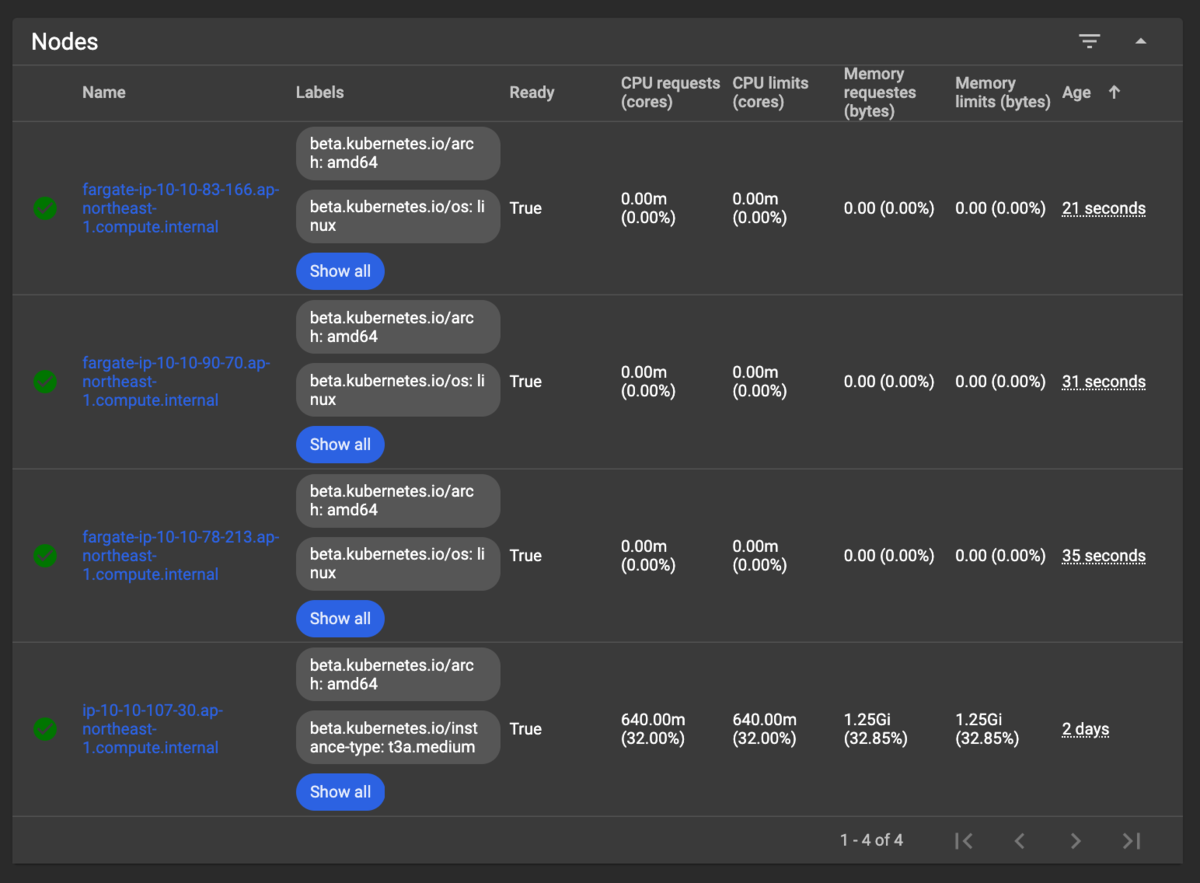
気になって夜も眠れなくなったので調べた結果、実際にIP専有してました...


これで万が一、cleanup-operatorが停止した場合、、、
- subnetを/20で作成すると、利用可能なIPアドレスは4,096弱
- az毎に1つsubnetを作成
- fargateで利用できるsubnetはprivateのみ
- 4,096×3=約12,000個のIPアドレス
- Jobが毎時500実行された場合、約24時間でIPアドレスが枯渇する!!😱
まとめ
- EKSのバージョンアップで、ttlSecondsAfterFinishedが使用可能になったら導入を検討しましょう...
最後に
いかがだったでしょうか、バッチ処理メインのEKSクラスターは、自分が知ってる限りでは事例がなくネット上でも情報がありません。
非常にニッチな情報共有となってしまいましたが、今回の件で地雷は踏み抜いた感があります。
これから導入を検討されている方や、すでに使われている方への一助となれば幸いです。
明日は18日目、UTさんです。お楽しみに!!
- https://gunosy.co.jp/news/161↩
- https://gunosiru.gunosy.co.jp/entry/gunosytechlab_dre↩
- この辺りの詳細な挙動について自信がないので、有識者の方にご教授頂ければ〜🙏↩
- https://kubernetes.io/docs/concepts/workloads/controllers/ttlafterfinished/↩
- https://github.com/lwolf/kube-cleanup-operator↩
- https://github.com/aws/containers-roadmap/issues/255↩
- https://qiita.com/mumoshu/items/c9dea2d82a402b4f9c31↩