この記事は Gunosy Advent Calendar 2017 4日目の記事です
はじめに
こんにちは、データ分析部のy-abeです。 パーソナライズシリーズの続きになります。
今回はワークフロー編です。 パーソナライズにおいてユーザーや記事の素性抽出や、モデル作成をするコンポーネントや記事リストを生成するAPIが必要です。 それらのコンポーネント間でうまくデータを取り回すためにはワークフローが重要です。 ワークフローは、いわばシステム上における兵站といってもいいでしょう。 「戦争のプロは兵站を語り、戦争の素人は戦略を語る」という名言もあるくらいです。
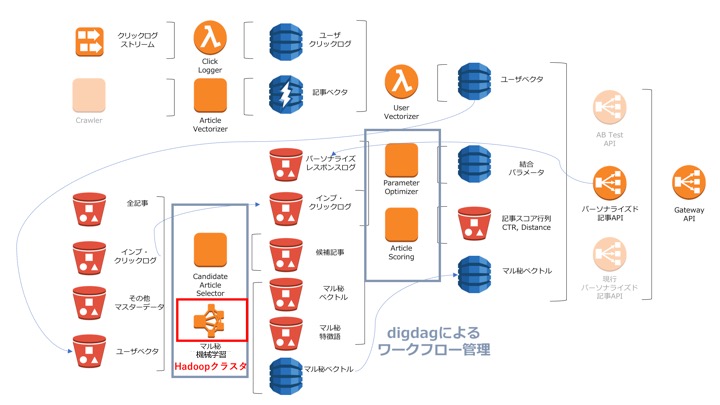
さて、パーソナライズ記事配信のタスクの流れをざっくりいうと、 ユーザーと記事の素性を集めて整形(ベクトル化) -> 機械学習でモデルを作成 -> 素性とモデルを利用し、ユーザー毎に記事リストを生成・配信 という流れになっています。 詳しい背景やアーキテクチャについては上で紹介した記事をご参照ください。
ワークフローがやることはバッチ系の各タスクを関連付けて実行することで、素性を集めるところとモデル作成を管理しています。 具体的には以下のことを行っています。
- 配信候補記事リストの作成
- Hadoopクラスタの起動と機械学習タスクの実行
- 記事スコアの計算
- ハイパーパラメータの自動最適化
今回は2番目に挙げたHadoopクラスタの管理について書いていきます。 (他のタスクは言ってみればスケジューリングをしているだけなので・・・)
候補記事生成やハイパーパラメータの自動最適化あたりの詳細については、またいずれ紹介したいと思います。
Hadoopクラスタの起動と機械学習タスクの実行
機械学習タスクは Spark on EMR で行います。 このタスクはバッチ処理なので常時起動させる必要は無く、また、たくさんのインスタンスを起動するため、結構なお金が飛んでいきます。 そのためクラスタはタスクが実行される都度作りタスクが終わった時点で停止させる運用をしています。
DigdagではEMRを直接操作できるオペレータがありますが、細かな操作(インスタンスプロフィール等)ができなかったため、EMRはPythonオペレータを使ってPythonのコードを実行しています。
タスクは以下のように切り出しました。
- EMRでHadoopクラスタを作る
- 機械学習タスクを行うステップを追加する
- モニタリング
- タスクが終わったら学習結果を通知して終了
クラスタを作る際、 KeepJobFlowAliveWhenNoSteps というオプションを False にしておき、全タスクが終了するとクラスタが停止するようにします。
モニタリングの段階では describe_cluster というメソッドを使ってクラスタのステータスを監視します。
クラスタのステータスが TERMINATING になることを検知して次のステップに進み、学習の結果を通知して終了します。
おわりに
今回はDigdagを用いたGunosyパーソナライズのワークフローについて紹介しました。 特に、EMRを利用して機械学習モデルを作成するフローについて取り上げました。 DigdagはPython以外にもShellスクリプトRubyなどにも対応しており、柔軟にワークフローを設計することができました。 Digdagは社内随所で利用されてきており、バッチ処理のみならずembulkと組み合わせて分析用のデータフローにも利用されています。 このあたりもまた後日紹介したいと思います。