はじめに
はじめまして、新卒の takuji と k.oshiro です。
今回は、新卒1年目エンジニアを対象とした研修プログラムである「AWS JumpStart 2023 for NewGrads 設計編」の概要と学んだことをお伝えします。
サマリー
- 2023年卒の新卒1年目エンジニアを対象とした、実践的な研修プログラムの「AWS JumpStart 2023 for NewGrads 設計編」に新卒研修の一環として、新卒メンバーの takuji と k.oshiro が参加しました。
- 本イベント(3日間)を通して、AWS サービスを使った基本的な構成や、可用性が高くてスケーラブルな構成に加えて、サーバーレスの構成までを学ぶことができました。
- アーキテクティング課題ではチームごとに構成図を作成してから、フィードバックを受けました。フィードバックでは、機能要件に合った最適な AWS サービスはどれで、全体的なアーキテクチャの実装も含めてどういう順番で作業をするかのような私たちが想定していた以上の解像度を求められていることを感じました。
- 今後は、「なぜ、選択肢がある中でその AWS サービスを選んだのか?」、「リクエストの入出力は何か?」、「どのような戦略でアプリケーションの変更またはアップグレードを可能にするか?」といった点を考慮できるように、構成図の粒度を細かくして検討できるようになることを目指します。
目的
AWS サービスのドメイン知識のキャッチアップと要件に合った適切なアーキテクチャを検討・設計する経験を積むことを目的としました。 また、新卒メンバーの takuji と k.oshiro が将来的に AWS 活用をリードする人材になるための第一歩をスムーズに踏み出すためでもありました。
やったこと
本イベントは2023 年 5/31 (水) - 6/2 (金)の3日間で行うワークショップ形式でした。3日間のイベントをより充実したものにするために、事前勉強用の録画動画で勉強しました(計4時間)。
1日目
講義
AWS で Web サービスを構築する場合、フェーズや目的によって目指すべきアーキテクチャは異なるので、どの AWS サービスを組み合わせて設計するかを、基礎となる仮想サーバー利用時の考え方にフォーカスして学びました。 具体的には、4つのフェーズで目指すべきアーキテクチャを確認してから、その構成における将来的な課題を知り、一般的な対策を学びました。 ここでの4つのフェーズは、プロトタイプのフェーズ、サービスを一般公開するフェーズ、多数のユーザーが快適に利用できるよう改善するフェーズ、それ以上に分けられていました。
ALB + ECS + RDS(Aurora MySQL) ハンズオン
本ハンズオンでは、可用性が高く、スケーラブルな Todo 管理アプリのアーキテクチャの設計図を通して、実際にアプリの構築を行いました。 本ハンズオンの狙いは、Web アプリ構築のイメージを持つことでした。
2日目
EC2 ハンズオン
Day1 で学習した内容を振り返った後、EC2 (仮想サーバー)のイメージを掴むためのハンズオンを行いました。 まず、AWS 管理コンソールを開いて、VPC (= 独自の仮想ネットワークを組めるサービス)を利用して、EC2 を稼働させるネットワークを構築することから始めて、EC2 管理ページより、EC2 インスタンスとセキュリティグループを作成しました。EC2 周りの設定自体は、Systems Manager の 高速セットアップから行い、Host Management の「作成」を押すことで完了します。その後、EC2 管理ページを開いて、セッションマネージャからインスタンスに接続し、管理者としてログインした後、Web サーバソフトの Apache を起動しました。最後に、EC2 インスタンス管理画面から確認できるパブリック IPv4 DNS をコピーして、Web ブラウザに先ほどコピーした URL をペーストして検索すると、無事 Web ページが表示されることが確認できました。
アーキテクティング課題(基本課題)
本課題では、AWS サービスを用いて、夕方から夜にかけてアクセスのピークを迎え、私たちが日頃利用しているような「とあるサービス」を設計し、構成図に落とし込みました。具体的には、このサービスにおける可用性*1とスケーラビリティ・パフォーマンス*2を意識しながら、提示された要件に合ったアーキテクチャを設計しました。
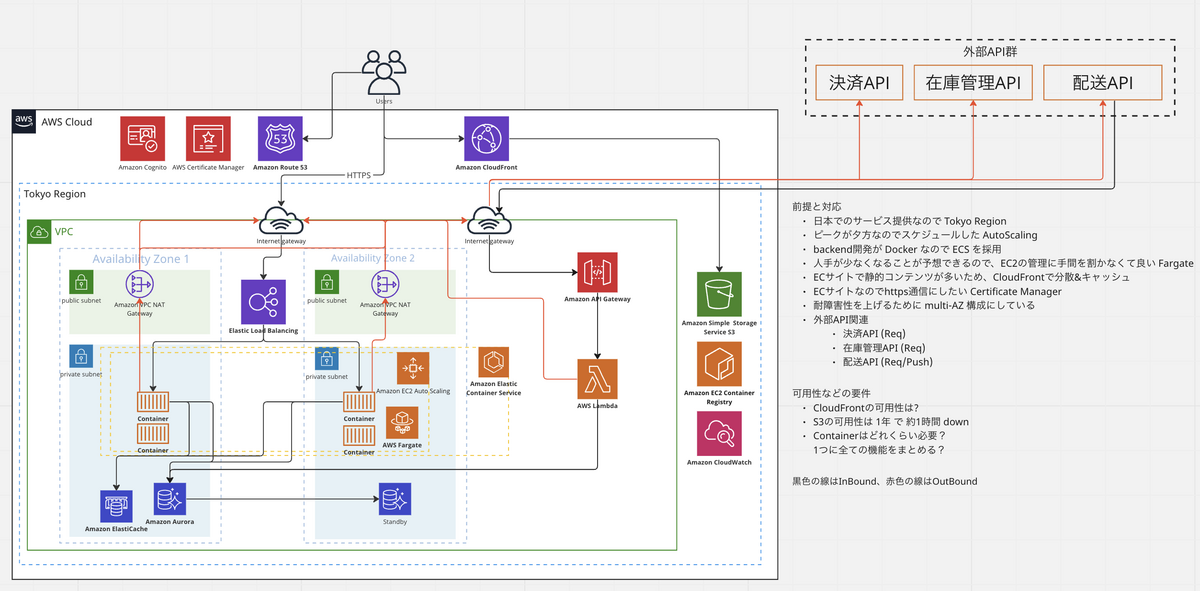
3日目
Serverless ハンズオン
本ハンズオンでは、Serverless アーキテクチャのイメージを掴んだ後、AWS Lambda、Amazon API Gateway、Amazon DynamoDB の3パートに分けてハンズオンを行いました。 上記で出てきた各 AWS サービスについて説明しますと、 AWS Lambda は、「関数」を様々なイベントをトリガーに実行できる特徴があり、従来のサーバーと異なり「常に待ち受け」はしないので、柔軟かつ低コストを実現できます。 Amazon API Gateway は、インターフェースの抽象化とアクセス基盤の統合ができる特徴があり、プログラムやソフトウェア同士がやり取りするための取り決め・仕様を決めて、サーバーレスな API を作成・管理を実現できます。 Amazon DynamoDB は、容量制限のない、完全マネージド型 NoSQL サービスという特徴があり、Read/Write それぞれにキャパシティユニットを設定できるため、様々な状況に柔軟に対応できます。
アーキテクティング課題(追加課題)
本課題では、Day2 の基本課題で提示された要件に加えて、Day3 では新たに追加要件が提示されたので、 それらの要件に合ったアーキテクチャを検討しました。 ここでの追加要件とは、開発者に加えて、分析者と利用者がより効率的に時間を使えるようにする機能要件でした。

得られたこと
takuji の学べたこと・知見
AWS全般
- リージョン内に地理的に離れた複数の AZ (Availability Zone)が用意されています。AZ は複数の DC (Data Center)から構成されています。
- IP アドレスを固定するには、グローバルIP アドレスサービスの「Elastic IP アドレス」を使います。Elastic IP アドレスは新規の EC2 インスタンスだけでなく、既存インスタンスにも適用できます。
- NAT ゲートウェイによって、プライベートサブネットからインターネットにアクセスできます。
- プライベートサブネットにおいて、DB インスタンスを直接設置することはありません。Amazon RDS は、DB サブネットグループで指定されたサブネットにインスタンスを起動されます。
- スケーラビリティ
- あるシステムが有する拡張性のことです。
- ユーザの要求する性能などに応じ、柔軟にその規模を拡大/縮小することが可能な場合、そのシステムは高いスケーラビリティを持ちます。
- 分散処理によりシステムを拡張することを「スケールアウト」、機器性能の向上によって拡張することを「スケールアップ」といいます。
- スケールアウト(水平スケール)
- Auto Scaling のように数の増減でスケーリングすることです。
- 例: EC2 を1つ → 3つ に変更する。
- スケールアップ(垂直スケーリング)
- インスタンスの性能を変更してスケーリングすることです。
- 例: EC2 インスタンスタイプを t2.micro → t2.large に変更する。
- Cognite 周りのやり取りは、Workshop Studio を見ると良さそうです。
- VPC 内のプライベートサブネットから S3 に直接アクセスできるように、VPC エンドポイントというものを使うことができます。
ALB・Auto Scaling
- ALB 等のロードバランサを使うことで複数台のサーバーに負荷を分散させることができます。
- ALB 等のロードバランサは、定期的にサーバーの生死を確認し (=ヘルスチェック)、 正常に動作しているサーバーにのみリクエストを渡します。
- ALB 自体に固定の DNS エンドポイントを AWS 側が準備するようになっていて、ALB まで到達させるために EIP は不要です。
- Auto Scaling で、AZ を追加・削除ということができるので、AZをまたいで Auto Scaling を有効化することが可能です。その後、インスタンスが終了してバランスが偏ったりする場合のために、 Availability Zones rebalancing のような機能もあります。
- 仮に片方の AZ 全てに障害が発生した場合は片側の AZ だけで動作します。Auto Scaling などを設定している場合は、徐々に片 AZ 側に十分な台数のサーバーが立ち上がるようなイメージになりますので、特に問題なく動作するというのが期待されます。
RDS
- RDS プライマリと RDS スタンバイを別々の AZ に分けて設置することで、別 AZ にデータを同期し、自動的にフェイルオーバーできて高可用性を担保できます。
- フェールオーバーは、あるリーダーインスタンスとライターインスタンスを入れ替える処理を指します。実際はライターインスタンスに問題が生じた際などに、フェールオーバーが実行されます。
- データの読み取り処理が多くなるサービスなら、読み取り負荷を分散するための「読み取り用レプリカ( RDS リードレプリカ)」を用意します。または、インスタンスのスケールアップなどで対応します。
- RDS リードレプリカは、RDS プライマリから非同期でレプリケーションされます。
- プライマリとリードレプリカの同期の速度は Aurora の場合、20msくらいのラグがあります。なので、書き込み直後に読み込みたい場合、プライマリに向けさせる方針を取らないといけません。
- レプリケーションラグは、書き込み操作が Read Replica に表示されるまでの時間のことです。
- デフォルトでは、プライマリインスタンスと Aurora Replicas 間のレプリケーションラグ値を表す AuroraReplicaLag メトリックが毎分 CloudWatch に発行されますが、レプリケーションの遅延が1 秒未満かを確認するには、毎秒この値を収集するカスタム CloudWatch メトリックを設定しないといけません(継続監視)。
- Read Replica に関連付けられたレプリケーションラグは、プライマリおよび読み取りレプリカインスタンスのワークロードプレッシャーに依存します。
- Aurora MySQL のリソースについて、片側 (Writer) が読み書き可能、もう片側 (Reader) は読み込み専用の データベースサーバーとします。
- RDB は構造上の問題で、単体インスタンスの性能に限界があるので、非常に大きい利用シーンかつRDBを使う必要があるなら、アプリケーション側で Partitioning のような仕組みを用意しないといけません(シャーディング)。
- 例えば、「id 0-65535 のユーザーが MySQL1 で、id 65535 以後のユーザーが MySQL2 」のように分ける感じ。
- AWS コンソールからリージョン別 DB クラスターを作成した時に、ステータスが作業中だと、両方のインスタンスがリーダーになることもあります。ステータスが利用可能になると、ライターとリーダーのインスタンスになります。
- オフロードとは、他のシステムに仕事を分けて、あるシステムに対する負荷を軽減させる技術のことです。
- 例えば、Amazon RDS プライマリインスタンスからの読み込みをオフロードするために、RDS Read Replica インスタンスを追加することによって、データベース容量を水平方向に拡大することができます。
CDN・Cache
- CDN の利用により、オリジンサーバーへのトラフィックをオフロード(解放)することができ、ウェブの応答性を高め、オリジンへの負荷を減らすことができます。AWS なら、Amazon CloudFront + S3 を使います。
- CloudFront + LB + EC2 + S3 を使う場合、アクセスはすべて CloudFront で受け取ります。CloudFront の設定で、キャッシュをしているコンテンツについてはキャッシュを返し、キャッシュをしていないコンテンツについてはオリジン( ELB や EC2 などで作ったサーバー)に送られます。
- CloudFront を ALB の前に置いて、URLのパスによってどのサービスを使うかを決めさせるような使い方をします。例えば、img のパスで画像を S3 側で取得し、それ以外をオリジン( ALB とその先のサーバーなど)で処理する等ができます。
- Amazon ElastiCache でもレプリカを作れます。
- EC2 で Auto Scaling Group を利用する場合には、セッション情報を ElastiCash に保管します。各 EC2 サーバーのメモリにセッション情報を保管していると負荷が少なくなって Auto Scaling の仕組みで EC2 サーバーの台数が減ったときにセッション情報が消えて、ログインし直しになってしまうことがあります。
- キャッシュはレイヤーごとに分かれています(概念があります)。
- HTTP レイヤーでキャッシュするのが、CloudFront 。
- アプリケーションレイヤーでキャッシュするのが、Elasticache 。
- DB の読み書きがある動的なサービスでは、CloudFront によって、APIからのレスポンスで JSON データをキャッシュできます。
- CloudFront + ALB の構成はネットワークの最適化の観点もあり、CloudFront からオリジン(後段のサーバー)までは、AWS が管理しているネットワークを通るので効率的に通信することができたりします。
- フロントエンドは、React 等を利用したSPAな構成をイメージする場合、Cognito を利用することで認証機能を実現できます( ELB 側で設定が必要です)。
コンテナ
- コンテナをつかってても「ローカルで動作してたけど、本番でだめだった」というケースとして、dev/prod の設定値の違いによるリリース時のトラブルがあります。そのほかには、Linux カーネルのバージョンが大きく異なる際に、一部の機能が利用できないや、x86 や arm 等 CPU のアーキテクチャが異なるので動かないなどがあります。
- あと、ローカルでは MySQL のコンテナを利用していたが、本番では Aurora MySQL を利用という場合や、本番は ALB 等のロードバランサが入るというような場合、微妙に構成が異なってくるので問題を引くこともあります。
- ECS のデプロイを早くすることはできないかについては、ECS でのコンテナデプロイの高速化 に詳しく書かれています。
ECR
- ECR はコンテナイメージを登録して置いておく場所( Docker Hub の AWS 版のようなイメージ)です。ECR はコンテナ系サービスを利用する際は、ほぼ必須のコンポーネントであります。
- まず、デベロッパーはローカル環境や CI・CD 環境で docker bulld コマンドにてコンテナイメージを作成します。続けてそれを ECR に登録します。
- 最後に、ECS の設定を変更してデプロイするのですが、ECS の設定変更の際には、ECR に登録したこのバージョンのコンテナイメージを使ってねという情報を付与してあげる感じになります。
ログ・ EC2 インスタンスの接続
- アクセス過多による負荷増加のモニタリングを CloudWatch で行います。
- 都度各サービスの画面を見るのは手間と時間がかかり、可視性に欠けるので 、CloudWatch のダッシュボード機能を活用します。
- Session Manger ではインバウンドポートを開くことなく、ブラウザや CLI からインタラクティブなシェルアクセスを実現できます。
- Session Manger の設定がインスタンスに反映されるまで、⻑い時は10分程度かかる場合があります。
- ログ情報はインスタンスのスケールダウン時に消えることから、後々にアプリケーションのログ調査などができなくなってしまうことを防ぐため、スクリプトを走らせて別の Strage に退避する方法が使われます。
AWS Lambda
- AWS Lambda の CPU 能力は確保するメモリの量に比例します。
- 処理時間が15分を超えると、タイムアウトします。なので、15分以内の処理かどうかが採用基準となります。
API Gateway
- API Gateway + Lambda というサービス群の組み合わせで、リクエスト数に応じた課金体型のシステムを構築します。
- API Gateway は、認証認可やパスに応じて複数の Lambda に振り分けを担当し、Lambda の上で、シンプルなアプリケーションコードを実行します。
- API Gateway 自体は、認証認可や簡単な流量制御などを実現できるので、API Gateway → ALB → ECS といった構成も可能ではあります。ただ、特段 API Gateway を挟まずとも ALB 側やアプリケーションサイドで実現できるケースも多いので、挟まなくて問題ないケースが多いそうです。
- 外部の API の場合、実行回数制限があったり課金性だったりするので、結果をしばらくキャッシュしておくのもありだそうです。
Amazon DynamoDB
- Primary Key 以外 Item 間で不揃いであっても問題がないらしいです。
- キャパシティユニットの考え方に関して、Read は1ユニットにつき、最大4KBのデータを1秒に1回読み込み可能であり、Write は1ユニットにつき、最大1KBのデータを1秒に1回書き込み可能であります。
- Read/Write それぞれのキャパシティユニットを要件に合った設定にして、「ピーク時は、1KB以下のデータが秒間80回書き込まれる」といった状況に対応するようにします。
アーキテクチャ構成
- 構成図を作る上で、まずUIのイメージを掴むことから始めます。
- 途中での設計変更は本番に反映しづらい and エラーが起きる可能性が高いので、初期の設計が重要です。
その他
- ビジネス価値に直接繋がらないが必要な作業が多いのがサーバーの管理らしいです。
- サーバーレスな設計によって、どこのネットワークにサーバーを立ち上げるとか何台立てよっかな、スペックどうしようかな、セキュリティ周り気をつけないとな、みたいなサーバー周りの話を考えなくて済みます。
k.oshiro の学べたこと・知見
オートスケーリングについて、メリットと制限
- オートスケーリングには、マシンスペックを変更するものと、マシンの数を変更するものの2種類があります。
- オートスケーリングのメリットは、リソース管理の手間が省け、無駄な課金を減らせることです。
- 一方で、プッシュ通知後にアクセスが急増する場合など、急な立ち上がりには対応しきれないといったノウハウも学べました。
Fargate は ECS のインフラとして利用可能なオプション
- もう一つのオプションとして EC2 があります。
- EC2 ではプロビジョニングやいくつかの設定を行う必要がありますが、Fargate ではこれらの必要がなく、サービスの開発に専念できます。
感想
takuji の感想
参加時点でどんな気持ちだったのか?
- 正直 AWS サービスは大学時代、周りの学生が研究で使っていたりもしていたけど私は全然知らなくて、AWS関連の会話には参加できていませんでした。
- 入社後は、AWS サービスを使って広告サーバー周りの運用をしているチームに配属されたけど、お気持ち程度しか理解できていませんでした。
どんなことが得られたらいいなと思っていたのか?
- 正直ほとんど知らないので、AWS サービスのドメイン知識
- AWS サービスを使った構成図の書き方、解釈の仕方
- AWS サービスの裏側の処理(構成図からは読み取れない部分の処理)
- 初期段階で気づかず、後々になってアーキテクチャで失敗したくないので、起こりうる問題
前後でどうなっていたいのか?
- AWS サービスをお気持ち程度しか理解できていない自分から、想定する機能要件に合った AWS サービスとアーキテクチャはこれだと言える自分になれたらいいなと思っていました。
実際のところ、どうだったのか?
- 400名近い参加者が気になった点を次々に質問してくれて、その回答を見ながら学べるので、キャッチアップが最短だった気がします。
- グループ作業になると、情報を集約できて、会話が楽しかったです。
- 他のグループの構成図を見ると、よりAWSの理解が深まりました。
- 質疑応答におけるAWSスタッフの回答の質が高かったです。
k.oshiro の感想
参加時点でどんな気持ちだったのか?
- EC2しか触ったことがないので、他のサービスについてはほぼ何もわからない。
- 構成図が複雑怪奇なものに見えていました。
どんなことが得られたらいいなと思っていたのか?
- 一般的によく使われるサービスの理解
- 基本的なアーキテクチャの理解
前後でどうなっていたいのか?
- 構成図を見て思考停止せずに、利用サービスの有効性や耐障害性まで考えて読み取ることができるようになりたいと思っていました。
- ユーザー数、使用技術に適したアーキテクチャの提案ができるようになりたいと思っていました。
実際のところ、どうだったのか?
- 研修の中で、よく使われるサービスが複数取り上げられていて、さらに質疑応答などでサービス間の差異を細かく説明していただいたおかげで、各種サービスの利用場面や有効性などを理解することができました。
- ユーザの規模を4つのステージに分けて、各ステージに対する構成例と想定される課題が挙げられていて、基本的なアーキテクチャに対する理解を深めることができました。
- グループでのアーキテクチャ検討会では、様々な要件に合わせてアーキテクチャを考えることの難しさ、楽しさを感じることができました。
- 社内のSlackにも質問を投げることで、SREチームの方から社内でのユースケースなどを教えていただいて、二重の学びを得ることができました。
まとめ
AWS JumpStart のような、講義形式のトレーニングに加えて、実践的な経験を積むことができるイベントに参加することで、AWS サービスを活用して要件に合ったアーキテクチャを設計・構築するための第一歩を踏み出すことができたと思います。本イベントは様々なバックグラウンドをもつ約400名の参加者が一緒に AWS サービスについて勉強できる場であり、AWS サービスについてざっくばらんに質問してもAWSスタッフの方々が全力で回答してくださいました。この場を借りて、感謝申し上げます。
最後に、これから、私たちは仕事で AWS サービスに触れる機会が徐々に増えてくると思うので、今回の学び・知見を活かして、チームに貢献していきます。
以上です。