こんにちは。部署が変わってプロダクト開発部の広告担当のUTです。 今回は障害が発生した経緯とその障害に対してどう対策したのかというところを紹介したいと思います。
概要
今回紹介するのは、設定(ConfigMap)を変更した際にコンテナ側が設定を読み込めなくなりコンテナが再起動、そして負荷が高まり連鎖的にコンテナが死んでいくという障害に関する話です。
別管理の設定が稼働するサーバーに反映されず、起動しなかったり実行時エラーになったりというのはよくある話ですが、今回はKubernetesにおけるConfigMapの設定でのエラーに関する話になります。
どのような障害が起こったのか
具体的にどのような障害が起こったのかを紹介していきたいと思います。
まず前提として障害が起こったサービスの技術スタックから紹介します。
- Kubernetes:サーバー構築はKubernetes上で行っています
- ConfigMap:設定の管理方法は色々あるかと思いますが、一番オーソドックスなConfigMapを利用しています
- Helm:yamlの管理はHelmで行っています。Kustomizeで管理しているサービスもありますが、今回の障害発生はHelm管理のサービスでの出来事です。参考: Istio Operatorやめました - Gunosy Tech Blog
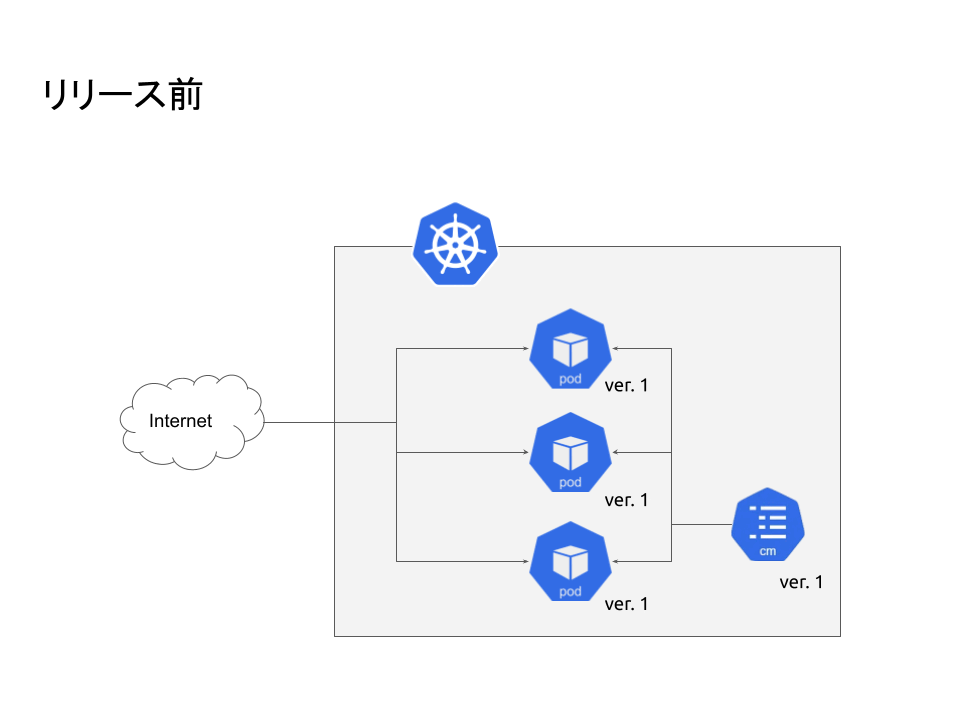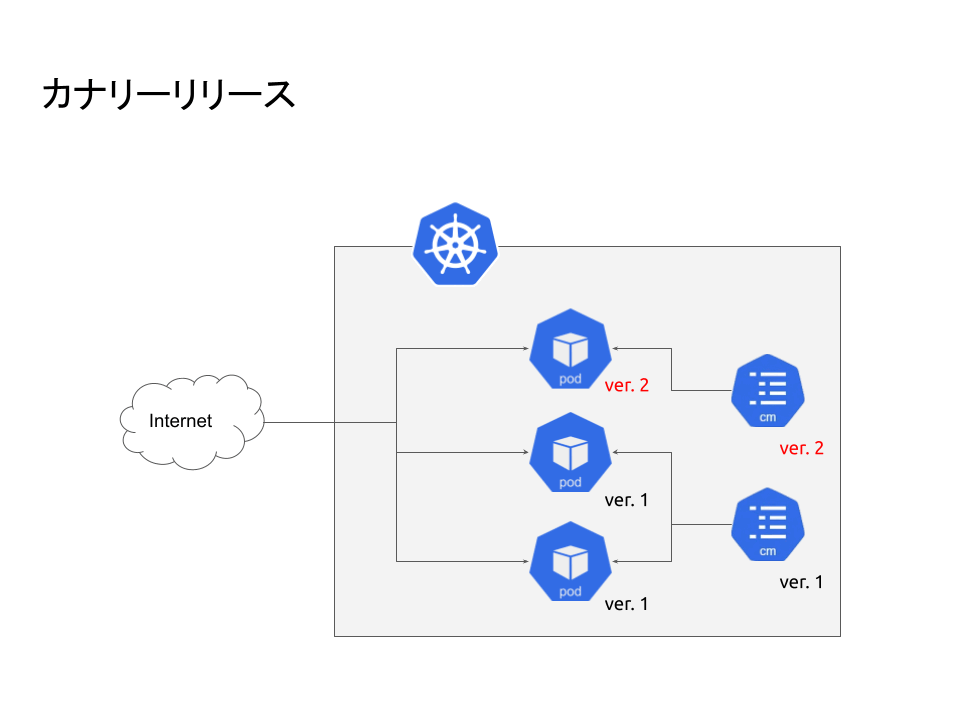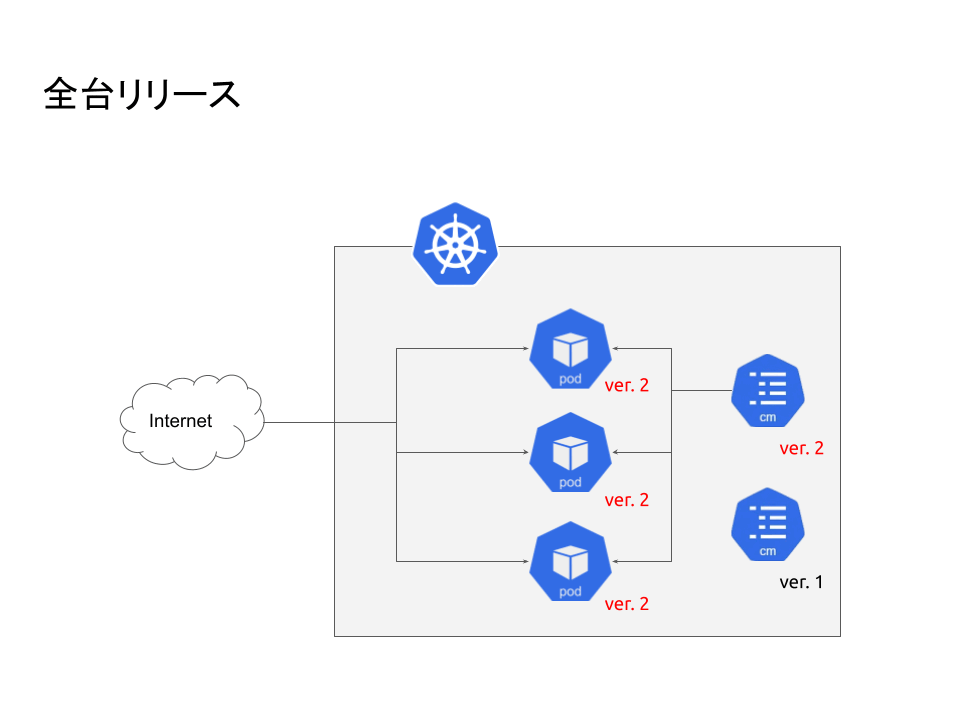
- Argo Rollouts:カナリーリリースを実施するためにArgo Rolloutsを利用しています。フローとしては指定Pod数(弊社では1Pod)リリースして問題なければ全Podロールアウトします。 参考: Argo RolloutsによるKubernetesでのCanary Deploy - Gunosy Tech Blog
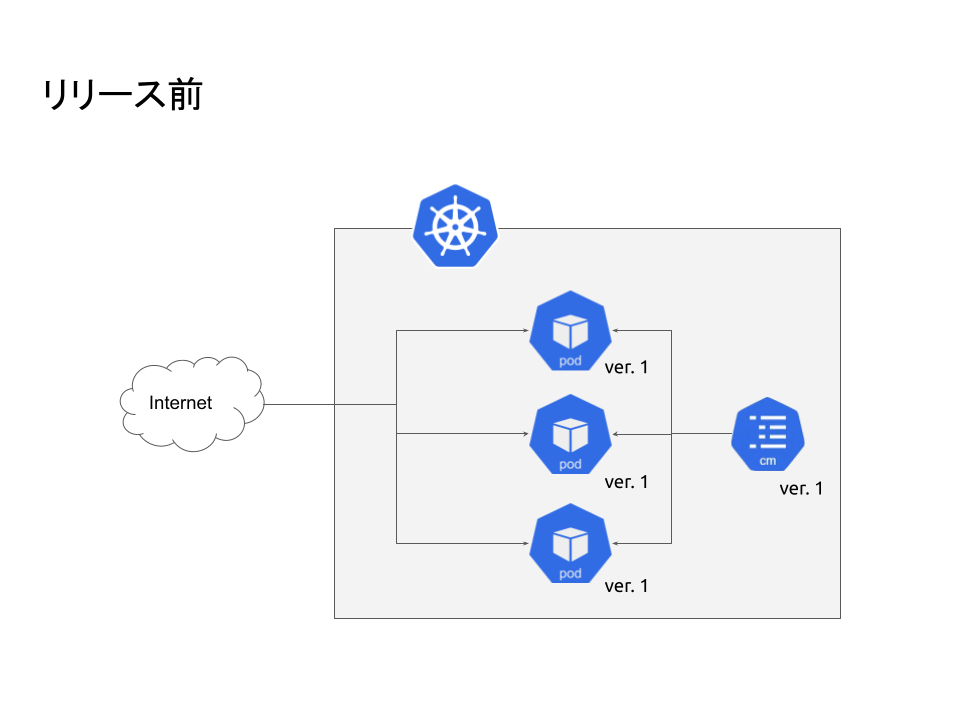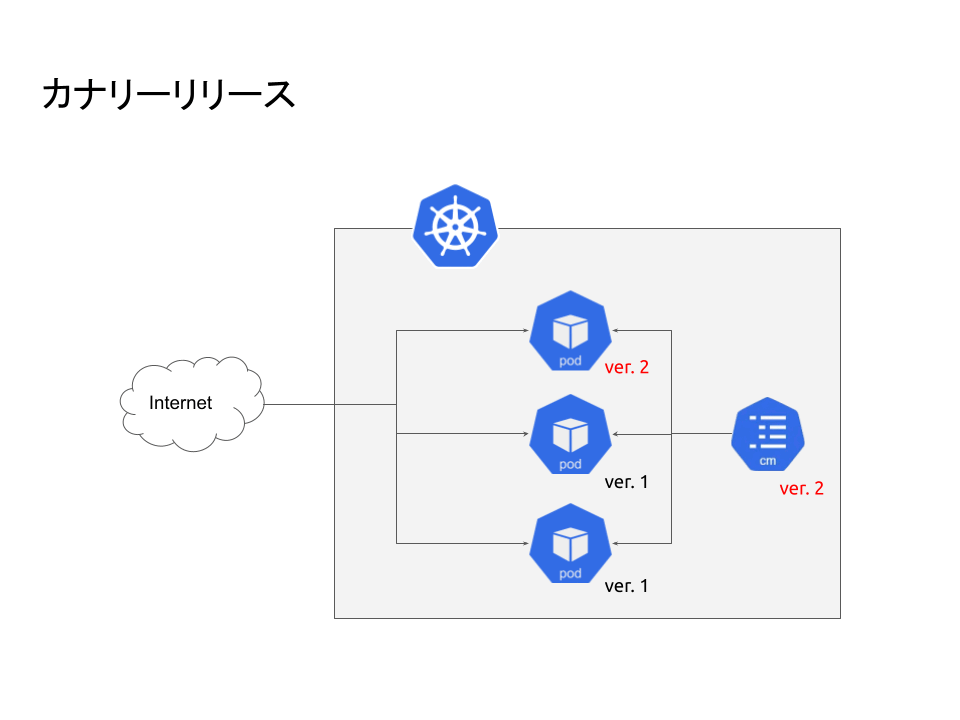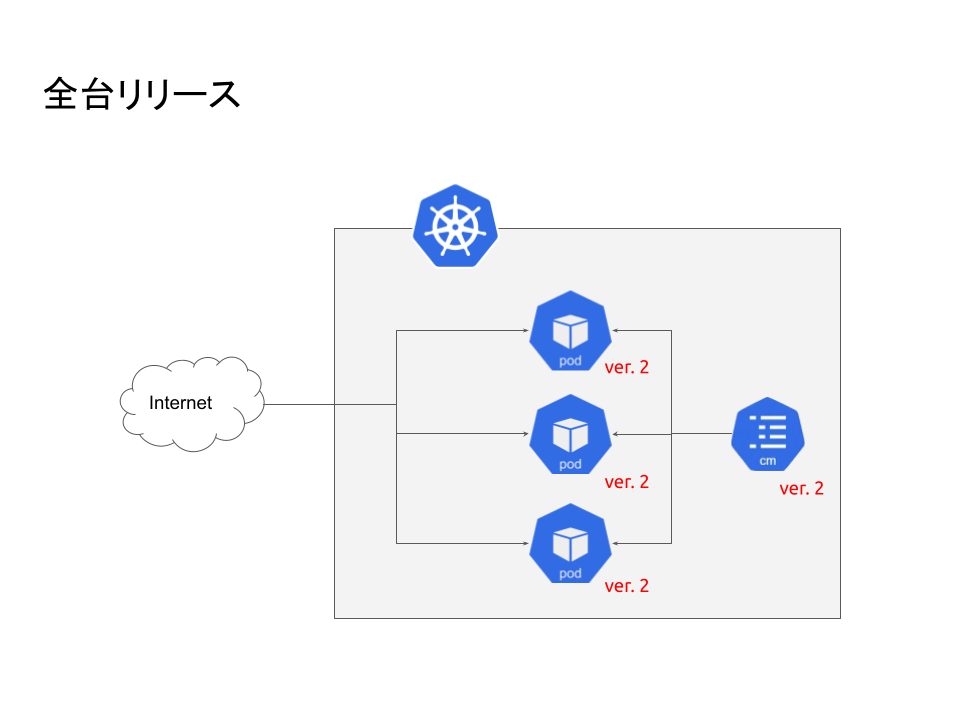
障害発生詳細
まず事象の背景を知っていただくために時系列で事象を紹介します。
- 障害発生当日の発生時間より前に古いDBを撤退させるため、ConfigMapとコードからその記述を削除するリリースを行っていました。
- リリースにはArgo Rolloutsによるカナリアリリースを採用しています。本来なら1Pod出てOKであれば全Podロールアウトするのですが、ロールアウト作業を忘れてしまい、1Podだけリリースされている状態でした。ここでHelm経由のリリースの場合、Podは新旧2つのバージョンが存在しますが、ConfigMapなどはデフォルトでは最新のみ保持されます。ただ通常であれば、サーバーはConfigMapの設定を起動時に読み込むので特に問題は発生しません。
- ニュース速報が発生。速報ではトラフィックが増えるため自動でPodがスケールします。Podが増える際、ロールアウトをしていないと旧Podがスケールし、新ConfigMapを旧Podが読むことになります。
- 旧Podのコードは古いDBを読むため古い設定を読む必要があるのですが、新ConfigMapしか存在しないため起動できません。
- 速報でトラフィックが増えますが、Podがスケールできないため既存のPodに負荷がかかり再起動がかかります。
- 再起動するとConfigMapを読み直すため、起動できずドミノ倒しのようにPodが次々と死んでいき、障害発生となりました。
恒久対応
障害の原因
ここで「古いDBをなくすってことは滅多にないから次は注意しよう」という振り返りでは、またすぐに障害は発生するでしょう。 人間の注意力ほど信用できないものはないので、再発させないためにも仕組み化する必要があります。
今回の根本原因は以下二点になります。
- 手動のロールアウト忘れ
- ConfigMapが最新しか保持されないことによる起動失敗
ということでこの二点をどう対応したかを紹介します。
自動ロールアウト
Argo Rolloutsの導入初期では、人がロールアウトのレバーを持たないと勝手にリリースされてしまっては困るという懸念があり、自動ロールアウトを設定していませんでした。
しかし、数年運用してきてむしろロールアウト忘れのほうが多く発生していると感じ、また大きめのリリースではそもそもdatadogなどの監視を見守っているため、ほぼ忘れません。
そこで自動ロールアウトを設定することのメリットのほうが大きいと判断し、自動ロールアウトするように設定を変更しました。
以下自動でロールアウトする設定です。 参考: Canary - Argo Rollouts - Kubernetes Progressive Delivery Controller
argoStrategy: canary: maxSurge: 1 maxUnavailable: 1 steps: - setWeight: 1 - pause: duration: 1h - setWeight: 100
ConfigMapが最新しか保持されない
こちらの問題はHelmの設定に起因するものです。 Helmに以下のようなアノテーションをつけると、過去のバージョンのリソースを保持するという設定があるので、その設定を導入します。 Helm | Chart Development Tips and Tricks
"helm.sh/resource-policy": keep
しかし、単純に設定をいれるだけでは
- 最新バージョンのみ保持
- 過去バージョンは全て保持
の2パターンしかなく、古いバージョンをローテートしてくれる機能はありませんでした。
そこで過去バージョンをローテートするためのHelm Pluginを作成、導入しました。
これはConfigMapの名前にリビジョン番号をいれておくと、そのリビジョン番号をもとに最新からの順番を確認し、対象外を削除という挙動をしています。
これを利用すると、過去のx個のバージョンのみ保持しそれ以外は削除する、という設定が可能になります。 CDの設定では以下のように設定しています
run: | helm plugin install https://github.com/mocyuto/helm-clear --version v0.2.1 skaffold run // helmによるデプロイ helm clear configmap "${HELM_RELEASE_NAME}" --namespace ads-api --history 5
まとめ
どちらの対応も現在安定的に稼働しています。 また今まではConfigMapの修正が入ってしまうと手動ロールバックができず、CI/CDからやり直す必要がありました。 しかしこれを導入したおかげでロールバックもCI/CDを通さずに素早く実施できるようになりました。
今回、サービス運営では切っても切れない障害の話でしたが、弊社では障害発生後、必ず人間の注意力ではなく仕組みでの恒久対応を検討しており、常に障害に強くなっていっていると感じています。
引き続き課題を解決していき、このように発信していければと思います。