こんにちは、m-hamashita です。最近 AdsML(DRE 兼務)から新規事業開発室に移って LLM 応用をしています。学ぶことが多くて楽しいですね*1。
この記事は Gunosy Advent Calendar 2023 の 20 日目の記事です。 19 日目の記事は田辺さんのデータアナリストが dbt seed を使って予算テーブルを作った話でした。
先日、広告のスコアリングサーバをフルリプレイスしました。その後、速報やリクエストが多くなるタイミングなどでエラー(タイムアウト)が急増することがありました。 今回はこのエラーの急増を解消した話について紹介したいと思います。 最初に背景とその原因を説明し、解決方法について紹介します*2。
広告スコアリングサーバのフルリプレイスに関しては以下の記事を参考にしてください*3。 tech.gunosy.io tech.gunosy.io
背景
広告配信サーバはその名の通り広告を配信するためのサーバです。広告配信サーバはスコアリングサーバに対してリクエストを送信し、広告のスコアや入札単価を取得しています。
スコアリングサーバのリプレイス後、速報やお昼時などリクエストが多くなるタイミングで大きな負荷がかかり、スコアリングサーバ側でエラー(タイムアウト)が急増することがありました。 Datadog を確認しても全体の平均 CPU 使用率等も高くなく、エラーが発生している原因がすぐにはわかりませんでした。
原因
結論から言うと、広告配信サーバとスコアリングサーバの Pod 数が AZ ごとに偏っていたため、同一 AZ 間通信による負荷集中が起きていました。

広告配信サーバからスコアリングサーバへのリクエストは、コストの観点で同一 AZ 内で行われるように設定しています。詳細はこちらの記事を参考にしてください。 tech.gunosy.io
AZ ごとの Pod 数に偏りがある場合、ある AZ の Pod に負荷が集中するといった問題が発生していました。 その一例を次に示します。
- 広告配信サーバ
ap-northeast-1aに 4 Podap-northeast-1cに 4 Pod
- スコアリングサーバ
ap-northeast-1aに 6 Podap-northeast-1cに 1 Pod
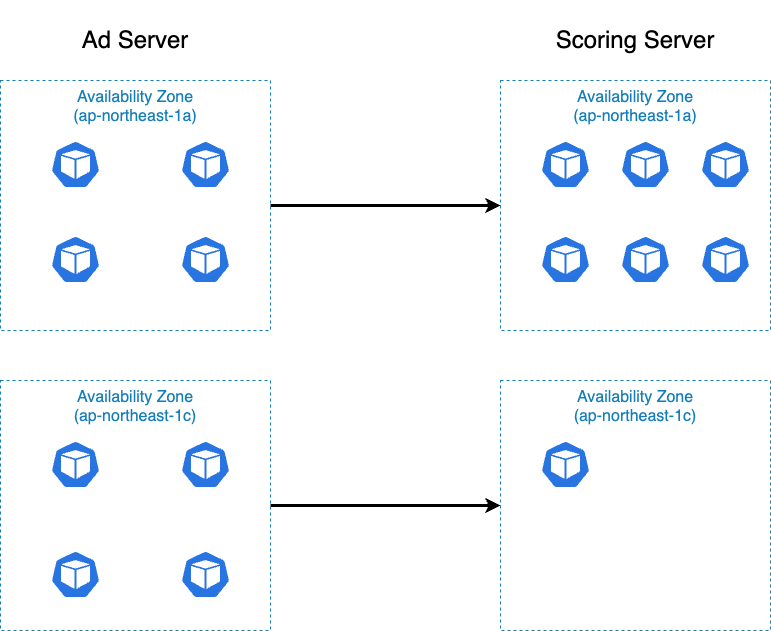
広告配信サーバへのリクエストは、均等にリクエストされると仮定します。このとき、先述の通り、広告配信サーバからスコアリングサーバへのリクエストは同一 AZ 内でおこなわれます。
この場合、スコアリングサーバの ap-northeast-1a では 4 Pod 分のリクエストが 6 Pod におこなわれ、ap-northeast-1c では 4 Pod 分のリクエストが 1 Pod におこなわれます。
したがって、スコアリングサーバの ap-northeast-1a では 1 Pod あたり、 2/3 Pod 分のリクエストを捌けば良く、ap-northeast-1c では 1 Pod あたり 4 Pod 分のリクエストを捌かなければいけません。
そのため、ap-northeast-1a ではリクエストが少なく、ap-northeast-1c ではリクエストが多くなり、エラーが発生するといったことが起きていました。
逆に ap-northeast-1a では CPU 使用率が非常に低く、無駄な Pod が起動している状態となっていました。
このように AZ ごとの Pod 数に偏りがあると、同一 AZ 間通信による負荷集中が起きてしまいます。今回はスコアリングサーバの Pod が偏っていましたが、広告配信サーバ側の Pod が偏ることも多々ありました。
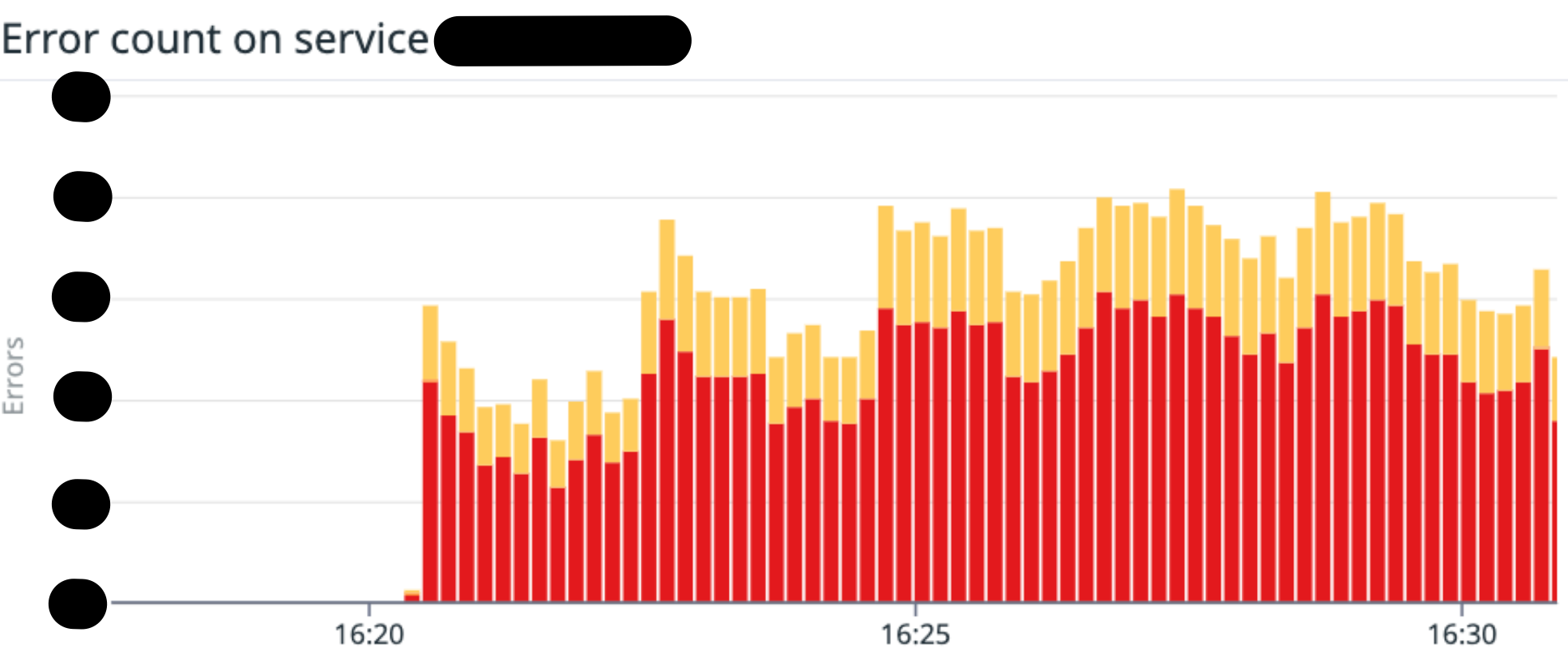
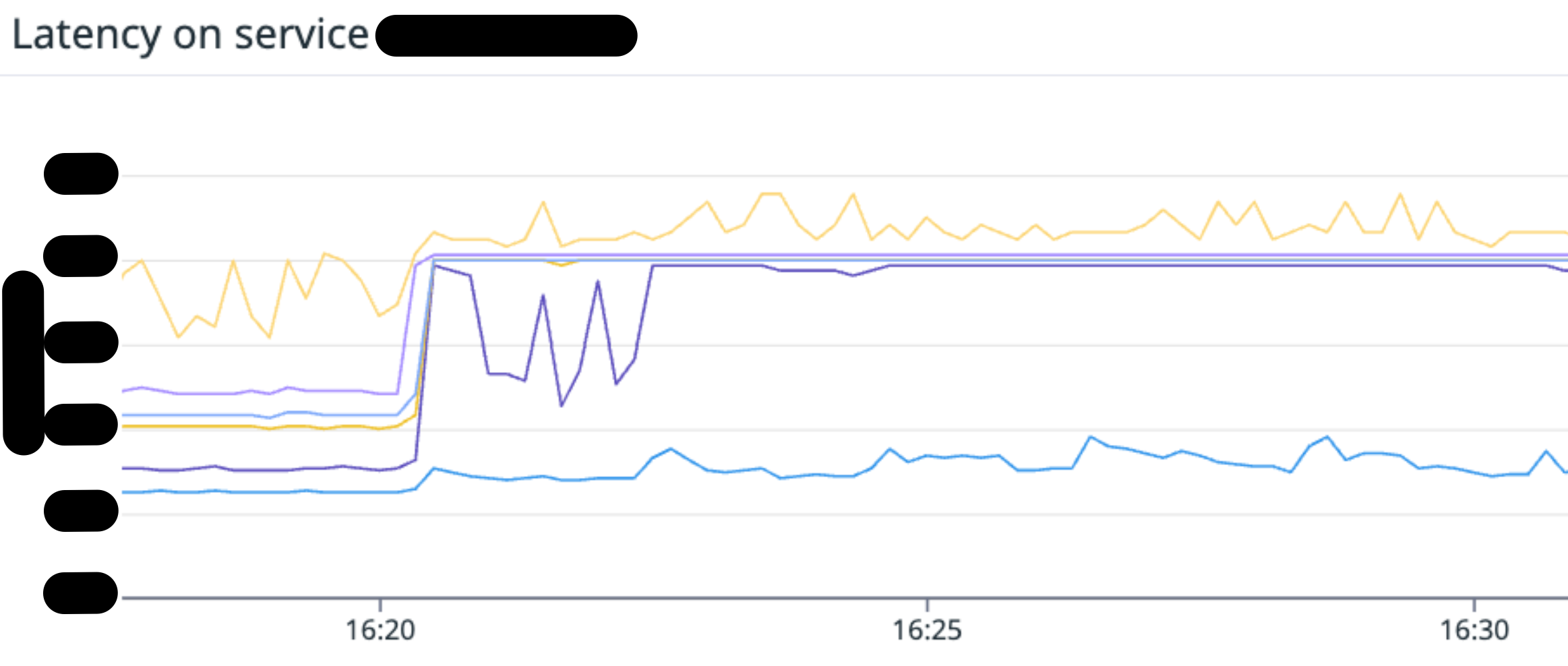
また、エラーがしばらく継続し、Pod がスケーリングしていないこともわかりました。つまり HPA(Horizontal Pod Autoscaler)がうまく機能していないということです。
HPA は平均 CPU 使用率で Pod 数をスケーリングするように設定しています。したがって、平均 CPU 使用率が閾値を超えていませんでした。
平均 CPU 使用率の計算は、Pod の CPU 使用量を Pod 全体のリクエスト量で割ることでおこなわれます*4。つまり、Pod が少ない AZ で CPU 使用率が高くなったとしても、他の AZ で CPU 使用量が少ない場合、平均 CPU 使用率は低くなります。
そのため設定した閾値に達せず、スケーリングしませんでした*5。
やったこと
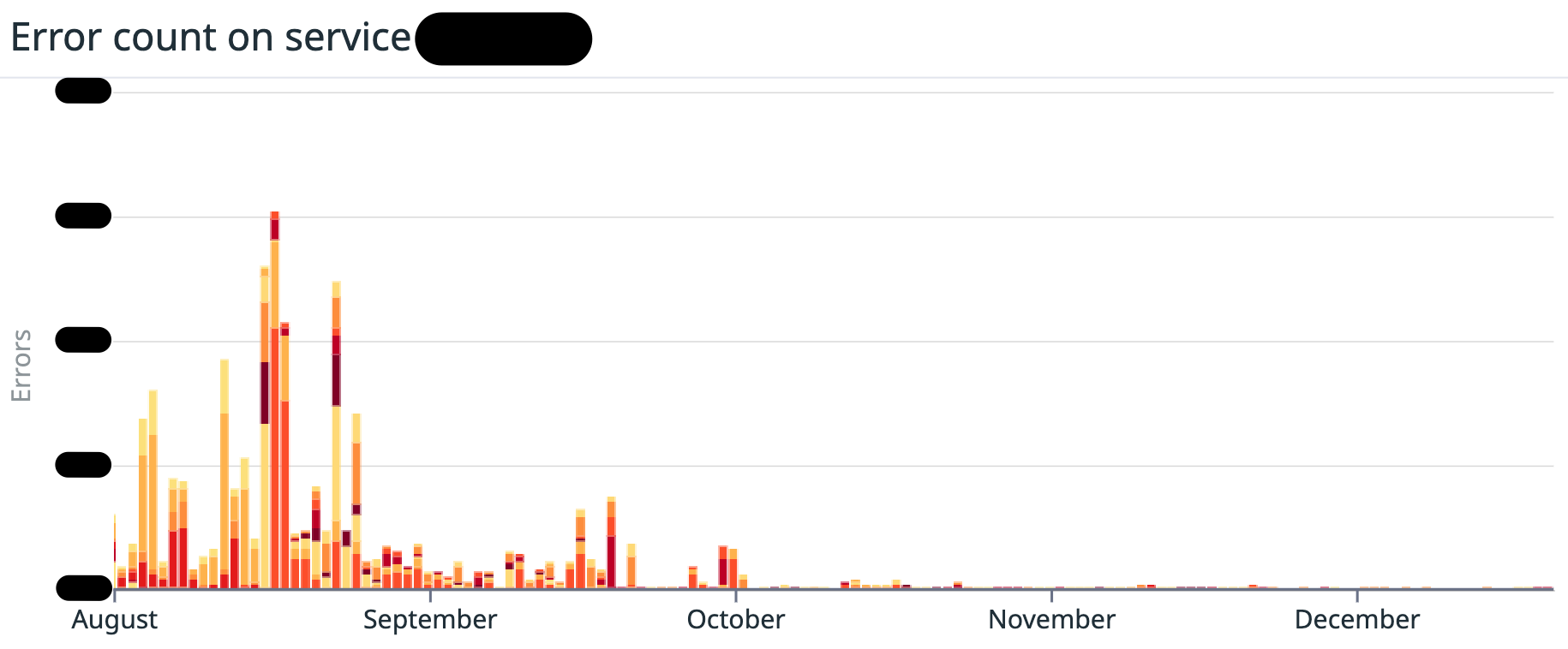
広告配信サーバ、スコアリングサーバの Argo Rollouts や HPA などを AZ ごとに設定することで解決しました*6。 今までは設定を AZ ごとにわけておらず、 Pod がどの AZ に配置されるかわからない状態でした。 今回この設定にすることで、AZ ごとに Pod 数が均等になり、負荷が集中することがなくなりました。 その結果、エラー数が大幅に減少して、最高の日々を送ることができるようになりました*7。
Helm の設定
次に具体的な設定について説明します。 AZ ごとに Argo Rollouts や HPA を設定するために、Helm の設定を変更しました。 広告配信サーバとスコアリングサーバの両方で設定をおこないましたが、設定方法はほぼ同じなため、広告配信サーバの設定を例に説明します。
values.yaml の設定
もともとの values.yaml の Node affinity には、以下のように AZ ごとの設定はありませんでした。
affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node_type operator: In values: - ad_server
これに対して、 AZ ごとに設定を追加します。今回は ap-northeast-1a, ap-northeast-1c の 2 つの AZ に Pod を配置するようにします。AZ ごとに設定が異なるため、affinities という配列に各 AZ の設定をおこなっており、 topology.kubernetes.io/zone で AZ を指定することで、AZ ごとに Pod を配置するようにしています*8。
az_suffix はラベルやリソース名に付与するために使われます。
# values.yaml affinities: - affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node_type operator: In values: - ad_server - key: topology.kubernetes.io/zone operator: In values: - ap-northeast-1a az_suffix: 1a - affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node_type operator: In values: - ad_server - key: topology.kubernetes.io/zone operator: In values: - ap-northeast-1c az_suffix: 1c
Argo Rollouts の設定
先述の values.yaml を用いて、Argo Rollouts の設定をおこないます。
もともとの Argo Rollouts の設定と異なる点は、Node Affinity の設定とラベルに az_suffix を追加することで区別しているという点です。
ループを使うとスコープが変わってしまうため、 . ではなく、 $ を使って値を参照する必要があることに注意してください。
{{ range $i, $affinity := .Values.affinities }} {{- if ne $i 0 }} --- {{- end }} apiVersion: argoproj.io/v1alpha1 kind: Rollout metadata: name: {{ include "ad-server.fullname" $ }}-{{ $affinity.az_suffix }} labels: {{- include "ad-server.labels" $ | nindent 4 }} az: {{ $affinity.az_suffix }} spec: {{- with $.Values.argoStrategy }} strategy: {{- toYaml . | nindent 4 }} {{- end }} selector: matchLabels: {{- include "ad-server.labels" $ | nindent 6 }} az: {{ $affinity.az_suffix }} revisionHistoryLimit: 3 template: metadata: labels: {{- include "ad-server.labels" $ | nindent 8 }} az: {{ $affinity.az_suffix }} annotations: {{- toYaml $.Values.podAnnotations | nindent 8 }} spec: serviceAccountName: {{ include "ad-server.serviceAccountName" $ }} {{- with $affinity.affinity }} affinity: {{- toYaml . | nindent 8 }} {{- end }} containers: # container の設定 {{- end }}
HPA の設定
Argo Rollouts と同様に、HPA の設定も AZ ごとに設定します。 HPA のターゲットとして、(AZ ごとに作成された)Argo Rollouts のリソース名を指定しています。これによって AZ ごとにスケールすることができました。
{{- if .Values.autoscaling.enabled }} {{ range $i, $affinity := .Values.affinities }} {{- if ne $i 0 }} --- {{- end }} apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: ad-server-rollout-{{ $affinity.az_suffix }} labels: {{- include "ad-server.labels" $ | nindent 4 }} az: {{ $affinity.az_suffix }} spec: scaleTargetRef: apiVersion: argoproj.io/v1alpha1 kind: Rollout name: {{ include "ad-server.fullname" $ }}-{{ $affinity.az_suffix }} minReplicas: {{ $.Values.autoscaling.minReplicas }} maxReplicas: {{ $.Values.autoscaling.maxReplicas }} metrics: {{- if $.Values.autoscaling.targetCPUUtilizationPercentage }} - type: Resource resource: name: cpu target: type: Utilization averageUtilization: {{ $.Values.autoscaling.targetCPUUtilizationPercentage }} {{- end }} {{- if $.Values.autoscaling.targetMemoryUtilizationPercentage }} - type: Resource resource: name: memory targetAverageUtilization: {{ $.Values.autoscaling.targetMemoryUtilizationPercentage }} {{- end }} {{- end }} {{- end }}
さいごに
今回は広告配信サーバとスコアリングサーバの Argo Rollouts や HPA を AZ ごとに設定することで、同一 AZ 間通信による負荷集中を解消しました。 力技ではありますが、解消することができてよかったです。もしスマートな解決方法があれば教えてほしいです。
明日は TksYamaguchi さんが Snyk を導入してコンテナセキュリティ対策の運用を回している話について書くそうです! Snyk 便利ですよね。とても楽しみです!
*1:一方で難しさも感じています
*2:本当は色々試したことがあり、紹介したかったのですが時間がありませんでした...
*3:この時からさらにレイテンシ改善をおこなっています
*4:参考: https://github.com/kubernetes/kubernetes/blob/0dc900cebe079efaf2087adc6fee6eb88d176020/pkg/controller/podautoscaler/metrics/utilization.go#L31-L49
*5:前述のケースで、ap-northeast-1a の各 Pod のリクエスト量が 10, 使用量が 2(平均 CPU 使用率 20%)、ap-northeast-1c の Pod のリクエスト量が 10、使用量が 10 の場合(平均 CPU 使用率 100%)、平均 CPU 使用率は 22/70=0.314... となり平均 CPU 使用率の閾値をかなり下げないとスケーリングしない
*6:今回のサーバでは Canary Release を行うために Argo Rollouts を利用していますが、通常の Deployment でも同様の設定が可能です。 Argo Rollouts を導入したときの話についてはこちらを参照してください
*7:修正前はよく PagerDuty が鳴っていましたが、設定後鳴ることはなくなりました
*8:参考: https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity