本記事は、Gunosy Advent Calendar 2020 8日目の記事です。
前回の続きとなります。
今回は後編として、実際にEKSクラスター構築の途中からアプリをデプロイする環境を整える流れをご案内し、最後に運用管理フェーズで必要となるであろうオススメ監視設定についてご案内します。
クラスター構築・後編(kube-system)
さて、EKSクラスターとASGも用意できたので、ここから作り込みを行っていきます。
まずはkube-system環境を整えていきましょう。
用途に応じて必須なものとそうでないものがあります。それぞれ表でまとめます。
| 対象 | 要否 | メモ |
|---|---|---|
| cluster-autoscaler | 必要 | fargateの場合は不要*1 |
| metrics-server | 必要 | HPA自体は必須ではないが、一般的なWebサービスの場合、コンテナでクラスタを構築する意味がなくなってしまう |
| kube-state-metrics | 必要 | クラスタの安定稼働のため、監視用途で必須 |
| datadog-agent | 必要 | 同じく監視用途として必須、ただしfargateの場合はdatadogをpodのsidecarとして動作させるため不要 |
| alb-ingresss-controller | 場合によっては必要 | クラスタでALBが必要なら、あった方が良い*2 |
| kubernetes-dashboard | 不要 | かつてはK8S管理のGUIツールとしてはデファクト・スタンダードだったが、いまはLensで代用するのがオススメ*3 |
| node-termination-handler | 必要 | nodeの停止とPodの再起動をスムーズに連携させ、サービスを停止させないために必要。fargateの場合は不要 |
| asg-lifecycle-manager | いまのところ必要 | ↑と同様な目的で必要だが、node-termination-handlerがこちらの機能を取り込みつつあり、いずれ不要となる予定*4*5。同じくfargateの場合は不要 |
| tiller-deploy | 必須 | helmのために必要 |
| external-secrets, external-dns | 場合によっては必要 | 使うならあった方が良いが、最初はなくてOK |
これらkube-systemのPodは、クラスタ全体の管理コンポーネントとして、kubernets provider*6を使ってTerraformでコード化*7*8し、インフラ用リポジトリで管理します。
なぜTerraformで管理するのか。コード化することによる構成管理以外にも、一度Terraformで作成したTerraformの状態管理化におかれたk8sのオブジェクトに対しては、コードが削除された場合には自動的に削除されるようになり、運用の効率化と構成の健全化が図れるからです。*9
各podのtemplate yamlからterraformのtfに変換するのは大変ですが、k2tfという変換ツールがあります。
kube-systemのpodが準備できた状態が、以下となります。*10
$ kubectl -n kube-system get po NAME READY STATUS RESTARTS AGE aws-node-d9694 1/1 Running 0 43h aws-node-ddpk4 1/1 Running 0 30h aws-node-qkdwx 1/1 Running 0 15d cluster-autoscaler-fbdb777b6-nlldg 1/1 Running 0 15d coredns-5674bf8d8-9hz2s 1/1 Running 0 15d coredns-5674bf8d8-hlttf 1/1 Running 0 5d1h datadog-agent-szpn4 1/1 Running 0 30h datadog-agent-bpdjx 1/1 Running 0 36h datadog-agent-hsn8w 1/1 Running 0 36h k8s-asg-lifecycle-manager-7b85747755-5qzzx 1/1 Running 0 15d kube-proxy-blpnt 1/1 Running 0 30h kube-proxy-lfskw 1/1 Running 0 43h kube-proxy-ql994 1/1 Running 0 15d kube-state-metrics-76d8c6c76b-qk4pj 1/1 Running 0 15d metrics-server-584bb4748d-52xxn 1/1 Running 0 15d node-termination-handler-b8hl5 1/1 Running 0 15d node-termination-handler-pdzg7 1/1 Running 0 43h node-termination-handler-qbshw 1/1 Running 0 30h tiller-deploy-7b65c7bff9-8qvjh 1/1 Running 0 5d1h
アプリのデプロイ編
いよいよアプリのデプロイに着手します。
アプリの開発と、コンテナビルド用のDockerfileの準備が出来ている前提で、解説を進めます。
Helm
まずはhelm(のchart)を整備します。 helmの構成については、こちらの記事:Helm Templateについて色々説明してみる - Qiita が詳しいです*11
templatesフォルダ以下にmanifestのkind(deployment, service等)毎のテンプレートとなるyamlを配置し、values.yamlには開発環境用のdefault値を入力しましょう。*12
前述の環境設計編のとおりに本番環境・ステージング環境・開発環境を分割した場合、環境毎にpodのresource設定やバックエンドサービス(RDS等の接続設定値)用configmapの設定値が異なりますが、各環境毎に異なる値を記述したyamlファイルをvaluesフォルダ以下に用意します。
フォルダ構成のイメージとしては、以下の様な感じです
$ tree first-app/ first-app/ ├── Chart.yaml ├── charts ├── templates │ ├── NOTES.txt │ ├── _helpers.tpl │ ├── deployment.yaml │ ├── ingress.yaml │ ├── service.yaml │ ├── serviceaccount.yaml │ └── tests │ └── test-connection.yaml ├── values │ ├── dev │ │ └── first-app.yaml │ ├── prd │ │ └── first-app.yaml │ └── stg │ └── first-app.yaml └── values.yaml 7 directories, 12 files
Skaffold
このhelmのchartをCircleCIなどのCI/CDツールと連携させて、対象のEKSクラスターに対して環境(prd, stg, dev)に合わせたvaluesを使ってapplyを行うよう制御してくれるツールが、skaffoldです。
skaffoldの概要や使い方については、こちらの記事:今度はあんまりゴツくない!?「わりとゴツいKubernetesハンズオン」そのあとに - Qiitaが詳しいです。*13*14
skaffoldは、コンテナのBuild+tag付け、リポジトリへのPush、HelmのChartを使ったmanifestを対象クラスタにapplyする、といった一連の処理を一括管理してくれる、Google謹製のK8S用開発支援ツールです。
helmでの使用例はこちら:https://skaffold.dev/docs/deployers/helm/
以下はアプリ用のPodがデプロイされた状態が以下となります。*15
$ kubectl -n <app用namespace> get deploy <deployment名> NAME READY UP-TO-DATE AVAILABLE AGE xxxxxxx 1/1 1 1 514d $ $ kubectl -n <app用namespace> get po NAME READY STATUS RESTARTS AGE xxxxxxx-75bb44cf9b-mv8tt 1/1 Running 0 27h
Podが正常起動していたら、アプリケーションの動作確認(Webアプリなら接続確認など)をしましょう。正常に処理されているのであれば、デプロイは成功です👌
監視運用編
最後に、サービスの安定稼働に向けた監視について、オススメの監視項目やメトリクスについてご案内します。
使用する監視ツールはdatadogとcloudwatchです。
事前にdatadog*16とcloudwatch*17*18*19 それぞれで、slackへの通知設定を行っておきます。
アラート設定
サービス安定稼働に向けたサービスレベルの維持管理のために必要な閾値監視について、個人的に最低限これだけあれば。というアラートを列挙します。なお、想定アプリは一般的なWebアプリです。
バックエンドの監視は含みませんので、ご自身の構成に合わせて適切なアラートを追加して下さい。
cloudawach
ほぼ全てのアラートはdatadogでOKですが、datadogの仕様上ELBはメトリクスの更新間隔が長くdatadog側での検知にタイムラグ(10分)*20があり、リアルタイムでの監視ができないので、cloudwachで行います。
Application Load Balancer の CloudWatch メトリクス - Elastic Load Balancing
HTTPCode_ELB_5XX_Count, HTTPCode_ELB_4XX_Count
- HTTPのレスポンスコードが5xxおよび4xxだった場合のカウント。アプリの許容エラー率を考慮して閾値を設定しましょう。*21
TargetResponseTime
- リクエストがロードバランサーから送信され、ターゲットからの応答を受信するまでの経過時間 (秒)。アプリの許容応答時間を考慮して閾値を設定しましょう。
datadog
datadogでは、主にEKSクラスター上で稼働するPodが正常に動作しているかどうかを、datadog-agentが取得したmetricsを元に、managed monitorで監視監視を行います。
CrashLoopbackOff[必須]
kube-state-metrics Unhealthy[必須]
- CrashLoopbackOffを始めとした、クラスター内の各オブジェクト(Pod, deployment, replicaset等)の状態監視を行うkube-state-metrics自体の監視です。
- 閾値は1以下です。監視間隔はkube-state-metrics自体の更新時を加味して、5分で様子を見ましょう。
- サンプルクエリ:
max:kubernetes.pods.running{deployment:kube-state-metrics}
Container Restart Count Increase[強く推奨]
- Podのコンテナの再起動の増加を検知します。CrashLoopbackOffにまでは至らないものの、なんらかの原因で一時的にコンテナが不安定となってしまった場合の検知に役立ちます。
- 閾値はアプリによりますが、3以上(過去5分間の合計)で様子を見ましょう。
- サンプルクエリ:
sum:kubernetes_state.container.restarts{*} by {container,namespace,pod}
Deployment Replicaset Count Descrease[強く推奨]
- replicasetのpod数が、なんらかの原因で設定した数以下となってしまっている状態を検知します。
- 閾値はreplicasの設定値次第ですが、50%(過去5分間の平均値)以下で一旦様子を見ましょう。
- サンプルクエリ:
avg:kubernetes_state.deployment.replicas_available{*} by {namespace,deployment} / avg:kubernetes_state.deployment.replicas_desired{*} by {namespace,deployment} * 100
Pod CPU and Memory Usage[推奨]
- PodのCPUとメモリ使用率が高騰していないかの検知を行います。閾値はアプリによりますが、80%(過去5分間の平均値)以上で一旦様子を見ましょう。
- CPUのサンプルクエリ:
avg:kubernetes.cpu.usage.total{*} by {namespace,pod_name} / ( avg:kubernetes.cpu.limits{*} by {namespace,pod_name} * 1000000000 ) * 100 - Memoryのサンプルクエリ:
avg:kubernetes.memory.usage_pct{*} by {kube_namespace,pod_name} * 100
dashboard
datadogでdashbaordを作成し日々の傾向を把握したり障害発生時に切り分けを行う場合に役立つ、NodやPodやコンテナのCPU/メモリなど一般的なmetrics以外に、EKS固有のおすすめメトリクスを列挙します。
なおdashboardは、namespace毎に作成するのがおすすめです。アプリ用namespaceと、kube-system用に分けましょう。
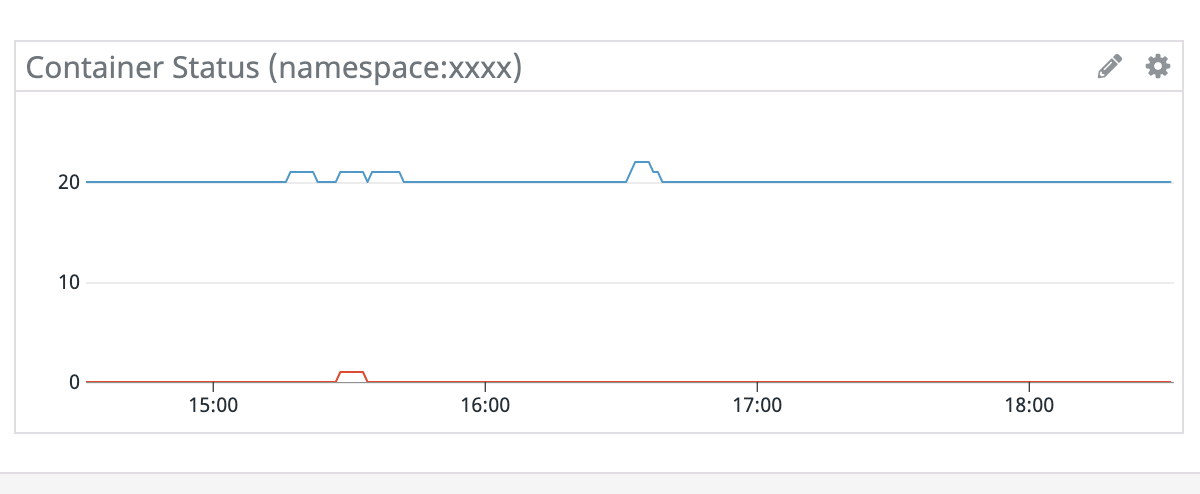
- Container Status
- コンテナのRunningとWaitingを一つのグラフに表示します。replicasetの更新時やHPAによる増減が把握できます。障害発生時には、左記のケース以外の意図しないコンテナの停止が発生していないか確認しましょう。*24
- Runningのサンプルクエリ:
sum:kubernetes_state.container.running{namespace:xxxx} - Waitingのサンプルクエリ:
sum:kubernetes_state.container.waiting{namespace:xxxx}
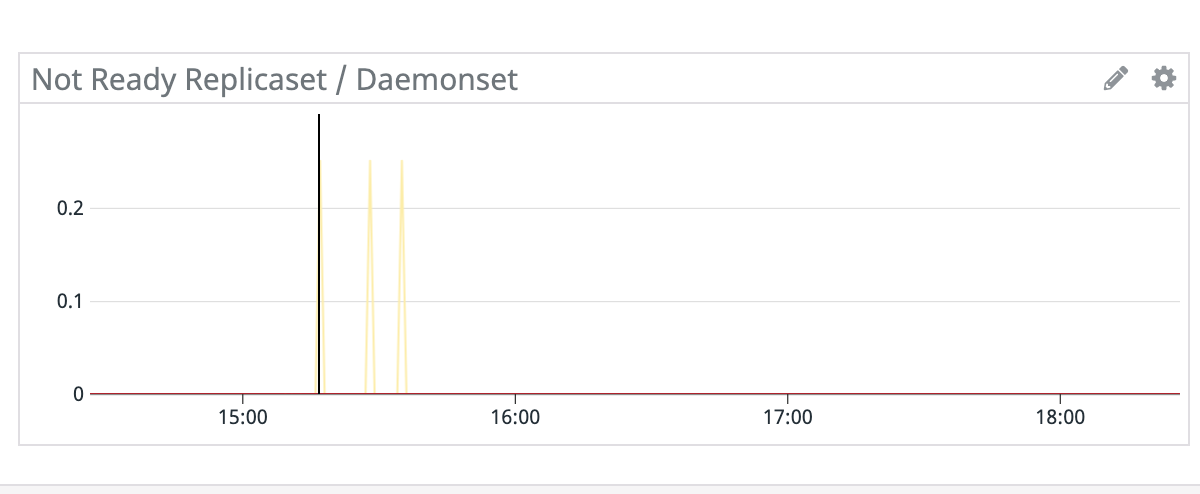
- Not Ready Replicaset / Statefulset / Daemonset
- ReplicasetやStatefulsetおよびDaemonsetで、起動していないPod数を表すグラフです。更新時には一時的にNot Readyな状態となりますが、ずっと継続している場合は何らかの異常が発生している事になります。
- Replicastのサンプルクエリ:
sum:kubernetes_state.replicaset.replicas_desired{namespace:<namespace名>} by {replicaset} - sum:kubernetes_state.replicaset.replicas_ready{namespace:<namespace名>} by {replicaset} - Statefulsetのサンプルクエリ:
sum:kubernetes_state.statefulset.replicas_desired{namespace:<namespace名>} by {statefulset} - sum:kubernetes_state.statefulset.replicas_ready{namespace:<namespace名>} by {statefulset} - Daemonsetのサンプルクエリ:
sum:kubernetes_state.daemonset.desired{namespace:<namespace名>} by {daemonset}-sum:kubernetes_state.daemonset.ready{namespace:<namespace名>} by {daemonset}
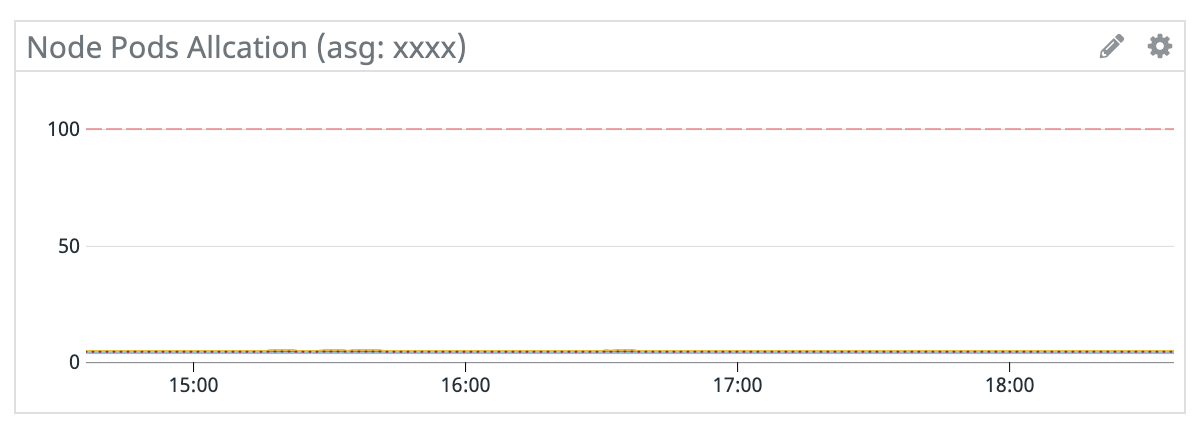
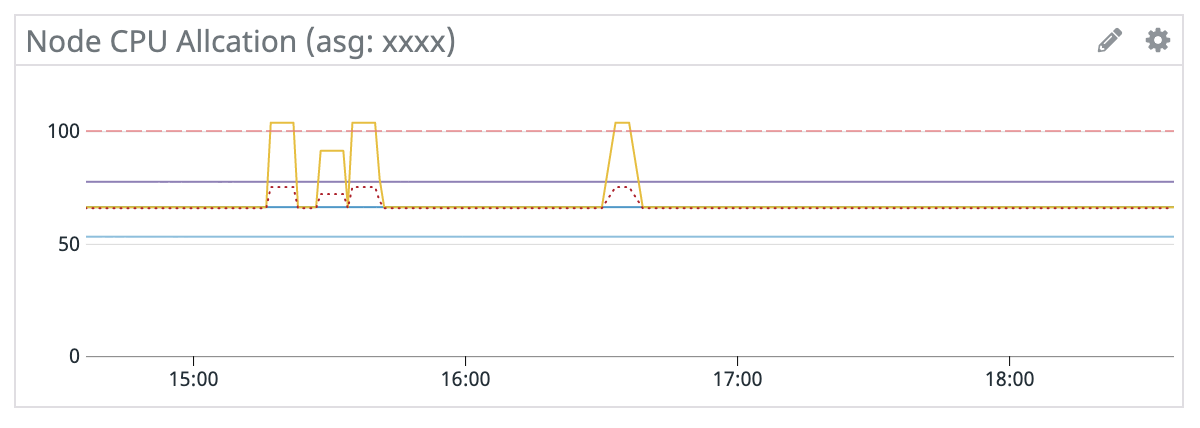
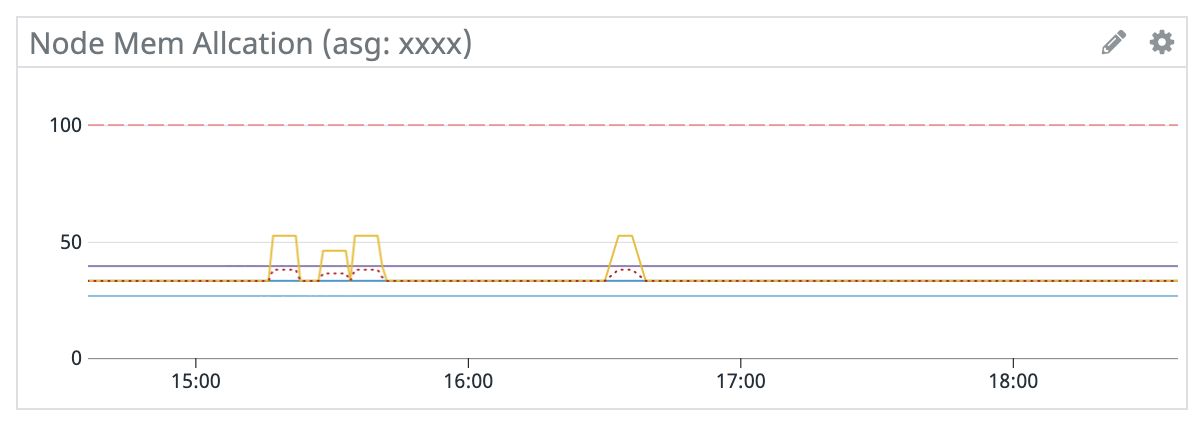
- Pod / CPU / Memory Allocation
- Nodeのインスタンスファミリー/サイズにより、起動できるPod数(EC2インスタンスのENI数)やコンテナのリソース(CPU、Memory)は限られています。1Nodeあたりのリソースをどれだけ消費しているか把握することができます。
- ASG毎にグラフを作ると良いでしょう。
- Podのサンプルクエリ:
100*(sum:kubernetes.pods.running{name:<asg名>} by {host}/sum:kubernetes_state.node.pods_capacity{name:<asg名>} by {host} - CPUのサンプルクエリ:
100*(sum:kubernetes.cpu.requests{name:<asg名>} by {host}/sum:kubernetes_state.node.cpu_capacity{name:<asg名>} by {host}) - Memoryのサンプルクエリ:
100*(sum:kubernetes.memory.requests{name:<asg名>} by {host}/sum:kubernetes_state.node.memory_capacity{name:<asg名>} by {host})
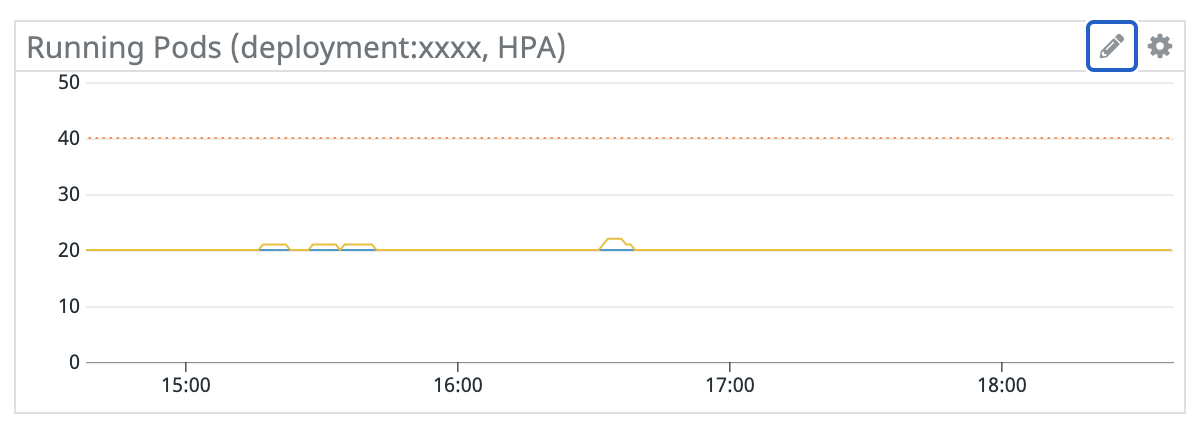
- HPA Status
- HPAの必要Pod数と実際のRunning数、TerminateされたPod数を一つにグラフに表示します。HPAの設定値(閾値等)が適切かどうか判断する事に加えて、Container Statusや Not Ready Replicaset / Statefulsetと比較することで、Podの増減が意図しない異常なケースかどうかを判断する事に役立ちます。
- HPAの必要Pod数のサンプルクエリ:
"sum:kubernetes_state.hpa.desired_replicas{hpa:<hpa名>} - 実際のRunning数のサンプルクエリ:
sum:kubernetes_state.container.running{container:<コンテナ名>,kube_namespace:<namespace名>} - 停止中のPod数のサンプルクエリ:
sum:kubernetes_state.container.terminated{container:<コンテナ名>,kube_namespace:<namespace名>}
さいごに
以上、長々とお付き合いいただきありがとうございました。
この一年で得た知識が、少しでもお役に立てたら幸いです。
続いては、johnmanjiro君の「terraformでEKSのManaged Node Group導入」です。
今回ご紹介したEKSのサービスをTerraformでコード管理する事がテーマなっており、大変タイムリーなお話となっています*25。是非ご覧になって下さい。
*1:オートスケールすべきEC2インスタンスが無いので
*2:K8Sバージョンアップ時にBlueGreenで行う場合は、ALBをK8Sの管理外に置く必要があるプロダクションレディを目指した Kubernetes クラスタのアップグレード戦略/Strategy to upgrade Kubernetes clusters in Production - Speaker Deck
*3:クライアントツールなのでpodの管理とALBの用意が不要
*4:AWS Node Termination Handlerの新機能について - Gunosy Tech Blog
*5:asg-lifecycle-managerは更新が停止しており、Forkしたこちらがオススメ:https://hub.docker.com/r/gunosy/k8s-asg-lifecycle-manager
*6:https://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs
*7:https://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs/resources/deployment
*8:automount_service_account_token = trueを忘れずに
*9:1つのPodを動作させる際には、本体のdeployment以外にservice account, clusterrole, role, clusterrolebinding, service, sercretなどの様々なresourceが必要となりますが、いざPod自体が不要になり削除する場合、Terraform化していないとそれぞれ1個ずつkubectl deleteコマンドでの手動削除が必要で、大変面倒なのと、よく忘れていつまでも不要なオブジェクトが残ってしまうケースが多々あるからです
*10:Runningは当然として、Restart カウントが増えていない事を確認して下さい
*11:というか全部書いてあります🙏
*12:kustomizeを使った人にとっては、templatesがbase、valuesがoverlayと置換えれば理解が速いと思います
*13:というか全部書いてあります🙏
*15:Runningは当然として、Restart カウントが増えていない事を確認して下さい
*16:datadog:Slackインテグレーションを使って情報共有 | Datadog
*17:cloudwatchは一般的な方法として、lambdaとchatbotを使う2パターンがある。お好みで
*18:https://qiita.com/hf7777hi/items/e0f43f0fb7e2effa0af8
*19:chatbot:https://www.skyarch.net/blog/?p=18439
*20:https://docs.datadoghq.com/ja/integrations/faq/aws-integration-and-cloudwatch-faq/#how-can-i-reduce-the-delay-of-receiving-my-cloudwatch-metrics-to-datadog
*21:例:アプリの想定最大リクエスト数が100,000rpm、許容エラー率を0.1%とした場合、許容できるエラー数は100となる
*22:https://docs.datadoghq.com/ja/agent/kubernetes/data_collected/#kube-state-metrics
*23:対象Podまでは判別できません(kube-state-metricsのpodが通知される)
*24:https://kubernetes.io/ja/docs/concepts/workloads/pods/pod-lifecycle/#container-states
*25:決して仕込みでは無い