はじめに
こんにちは、グノシー事業部でAndroidアプリとバックエンドの開発をしている山本です!
今回は先日リリースしたグノシースポーツ(以下 グノスポ)で導入したAWS AppSync(GraphQL)について紹介します。
グノスポの概要については当連載の第一回を御覧ください。
AWS AppSyncについて
AWS AppSync(以下 AppSync)とはAmazon Web Service(AWS)上で利用できるフルマネージドGraphQLサービスです。
AppSyncでは大まかに言うと、以下の事ができます。
- クライアントからのGraphQLを用いたアクセス
- 複数データソースからのデータ取得(query)
- Lambda
- DynamoDB
- Elasticsearch
- HTTP
- データの更新処理(mutation)
- リアルタイム通知(subscribe)
- Cognitoでのアクセス制御
各データの流れは以下のようになります。
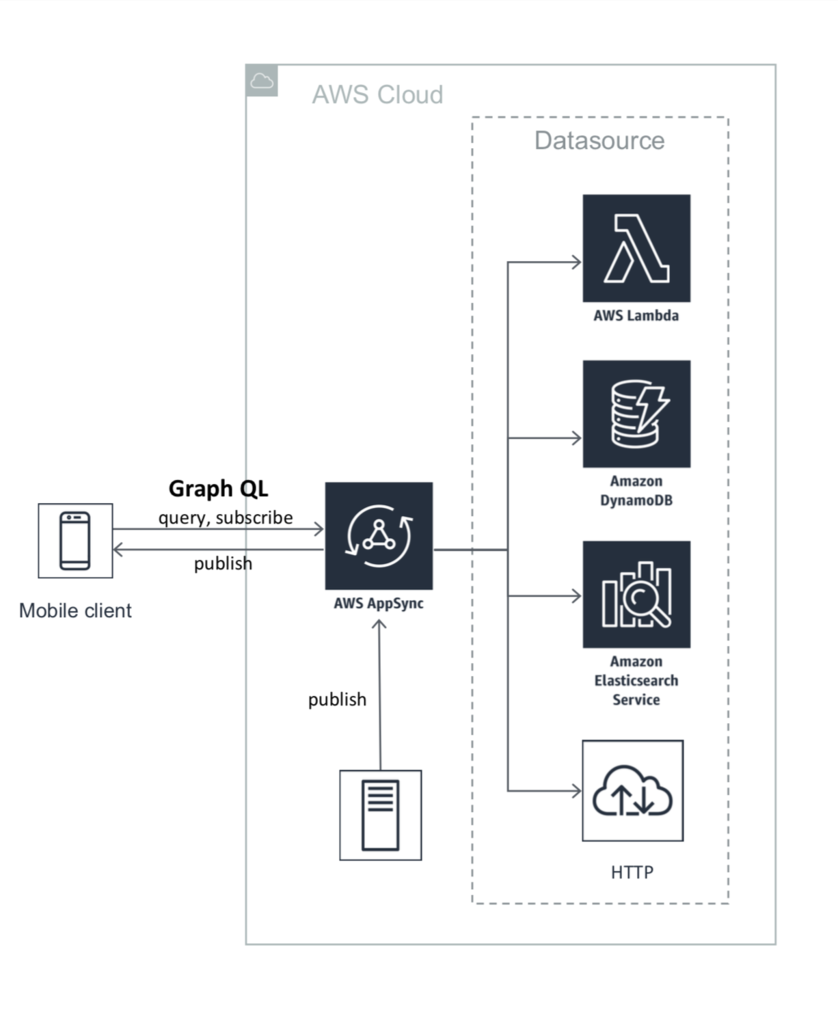
これまでのバックエンド開発では、データソースからデータを返すためには、純粋なデータ取得部分以外にも、サーバーの設定を記述したり、実際にデプロイする工数がかかっていました。
AppSyncを用いると、GraphQLで渡ってくるパラメータをどのように各データソースに渡すか、データソースのレスポンスをどうマッピングするかを定義するだけで、自動でスケールするサービスを簡単に構築することができます。
モバイルアプリとGraphQL
弊社のバックエンド/フロントサイドエンジニア間のAPIインターフェースの共有は、これまで以下のいずれかの方法で行われていました。
- github wiki等の手動編集
- swagger.jsonの共有
- apiaryやpostmanを用いた共有
しかし、いずれの方法でも更新の手間があるため、小さな修正では変更が追従されないといった問題がありました。
その問題への対処として、弊社ではgoでAPIサーバーが書かれることが多いので、goa を用いたswagger.jsonの自動生成/共有を行ってきました。それでも結局は、swaggerの仕様を手作業でクライアントの実装に移すため、OS毎に差異があるなどの課題がありました。
今回紹介するGraphQLを用いた開発では、.graphqlファイルをバックエンドとクライアントサイドで共有することによってこの課題も解決することができます。以下でどのように問題が解決されるかを説明します。
例えば以下の.graphqlファイルをバックエンド/フロントエンジニア間で共有します
type Article {
id: Int!
authorName: String!
title: String!
url: String!
}
type Query {
getArticleById(id: Int!): Article!
}
( ! はnonnullを指します)
このときクライアントエンジニアは特定の記事のtitleを知りたい場合
query GetArticleTitleById($articleId: Int!) { getArticleById(id: $articleId) { title } }
というクエリを書けば、関連ファイルが自動生成され、簡単に以下のような型安全なtitle取得コードを書くことができます。
// Androidでの実装例 fun getArticle(id: Int): Single<String> { return client .query(GetArticleTitleByIdQuery(id)) .asSingle() .map { it.articleTitleById.title() } // スキーマでtitleの定義がString!だったため Stringのnonnullになります }
以上のようなコード生成は、AWS公式のAppSync SDKを導入するだけで実行可能で、Cognitoとの連携なども公式SDKを使えば簡単に行うことができます。
また、type間の関連を定義しておけば、SQLにおけるjoinのような複数テーブルにまたがったクエリも可能です。 たとえば、グノスポでの利用例を挙げると、フォローしたチーム一覧とそれぞれに関連する記事、試合予定の取得は
query GetFollowedTeamDetails {
getFollowedTeams {
name
...
articles {
title
...
}
games {
startAt
...
}
}
}
のように記述することができます。 このように、APIの利用側が必要なデータを柔軟に選択でき、一回のリクエストで複数のデータを取得できるのもGraphQLにおける大きな利点と言えます。
グノスポにおけるAppSyncの利用方法
今回グノスポでは上記のような利点があるためAppSyncを全面採用しました。
フロントエンドとAppSyncまわりの大まかな構成は以下のようになります。
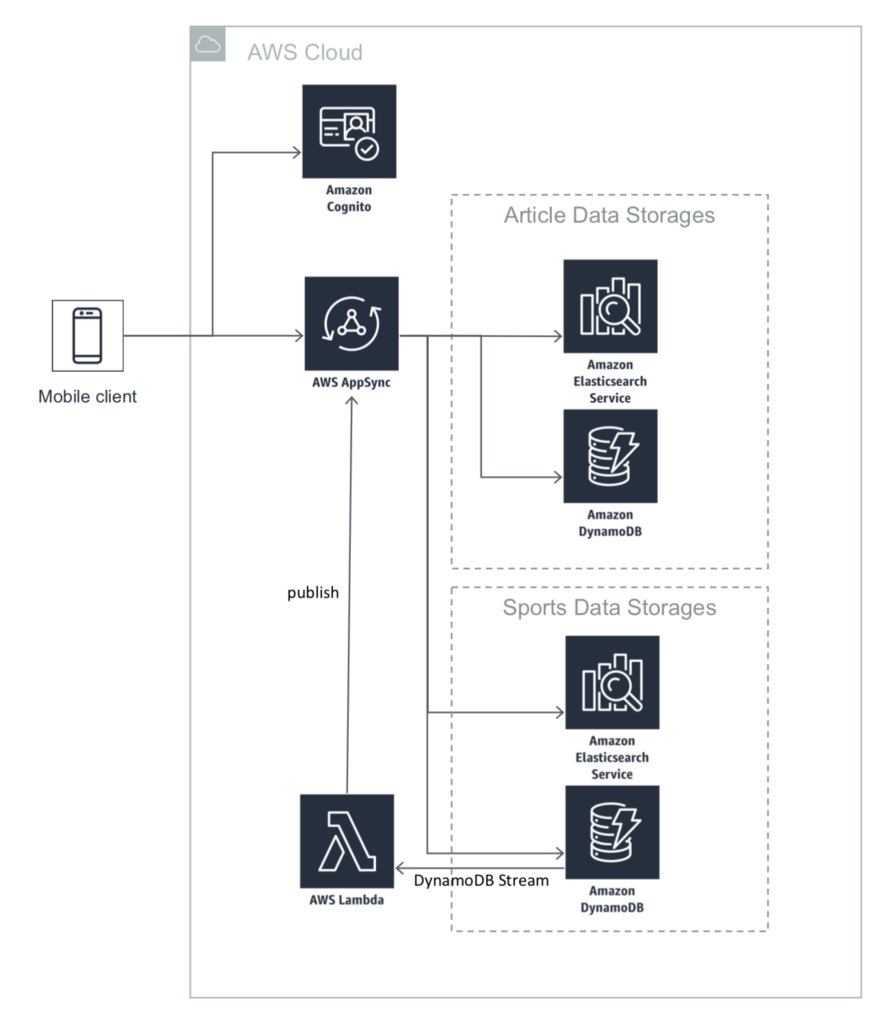
テキストで書くと
- データの取得
- フォローしたチームの取得 (DynamoDB)
- 記事の検索 (Elasticsearch)
- チーム情報(試合, ランキング) の取得
- データの送信
- フォローチームの設定
- プッシュトークンの送信
- リアルタイム変更検知
- 試合状態の変更通知
を主にAppSync経由で行っていることになります。 試合のリアルタイム通知には、DynamoDB Streamを用いて試合状態が変わったらlambdaに通知が飛び、そこからAppSyncのsubscriberに通知するといった流れになっています。
リリースして時間が経っていないので、運用上の問題はまだこれから出てくるとは思いますが、基本的にはDynamoDBのキャパシティを変えれば自動でスケールするサービスになっており、運用コストも低く抑えられるかなと思っています。
AppSyncの利用上の注意点
ここまでAppSyncの利点を述べてきましたが、少なからずAppSyncにも利用上の注意点があります。
- データのキャッシュが難しい
- AppSync ↔ DynamoDBの通信はキャッシュされず、DAXの利用もできません
- Readの多いデータだとそれなりなキャパシティーが必要になります
- Readの多いデータは、サーバーを立ててHTTP sourceにする or lambdaでキャッシュする必要があります
- サーバーレスの意味が薄れてしまう…
- AppSync ↔ DynamoDBの通信はキャッシュされず、DAXの利用もできません
- データソースとGraphQL間のマッピングを書くのが難しい
- データソースの結果をどのようにGraphQLで返すかはApache Velocityと呼ばれる聞き慣れない言語で記述する必要があります。
- このマッピング設定ファイルの文量がそれなりに多く、現状でも数千行あります…
- GUIでよしなに作れると嬉しいかもしれない
- レスポンスが少し遅い
- AppSyncのデータソースにlambdaを使うと当然のことながらコールドスタート問題があります
- クライアントSDKがまだまだ発展途上
- MutationやSubscribeを使うとメモリリークの問題やメインスレッドを専有する問題が発生することがあります
まとめ
今回はグノスポで利用したAppSyncの紹介と、当アプリ内での利用方法について取り上げました。 AppSyncを用いると簡単にサーバーレス/フルマネージドなGraphQL APIを構築できるようになります。クライアントで柔軟にデータを取得する必要があったり、リモートDBを気軽に使いたい場合は検討してみる価値はあるかと思います。
次回の連載第三回は、グノスポのデザインに関してになります!お楽しみに!