はじめに
グノシー事業部でサーバーサイドの開発を担当している吉澤です。好きなスポーツは釣りです🎣
今回第4回目のグノスポ記事は、サーバーサイドのアーキテクチャについてです。グノスポではサーバーレスアーキテクチャを採用しています。言語はほぼkotlinです。 それぞれ採用した理由や技術要素について説明したいと思います。
その他のグノスポ記事はこちら
サーバーレスにした動機
AppSyncベースでいくと決めたこと
第二回で紹介したようにAppSyncを採用したため、それを中心にアーキテクチャを考える必要がありました。 AppSyncの利用は以前グノシーライブ開発時にも提案されていたのですが、正式リリース前だったため採用を見送ったという経緯があります。
AppSyncはデータソースにDynamoDB, Elasticsearch Service(ESS), Lambda, HTTPが使えます。(つい最近Aurora Serverlessが追加されました。もっと早く来てほしかったです…)
HTTPデータソースを使えば実質なんでもデータソースにできるということになりますが、AppSyncで柔軟にqueryを追加したり削除したりするのとAPIサーバを別途開発するのではスピード感を犠牲にしてしまいそうだと考え、なるべくDynamoDBやESSに入れたものをとってくるだけにしようと考えました。
リソースが限られていたこと
理由の大半を占めるのが開発リソースの少なさでした。 グノスポは特定の領域に特化したバーティカルアプリではありますが、サーバー側に必要な要素はグノシーなどの他のアプリとあまり変わりません。
- クローラー
- 記事のトークナイズ・分類・タグ付け
- プッシュ基盤
- ログ・分析基盤
- API (今回はAppSyncなので不要)
最低限上記のシステムが必要になります。 この中でプッシュとログ・分析基盤はグノシーアプリでもKinesisやSNSなどを使ってサーバーレス化出来ていましたが、クローラーや記事分類はサーバーを立てて定期的に実行している状況です。
これらを少ない人数で開発するために、
- 分担しやすい構成にしたい
- デプロイ周りをシンプルにしたい
- サーバー台数やスペックの見積もりとかしたくない
- ワークフローの管理の手間をなくしたい
という理由で、必要なタスクを責務の小さいlambdaに分解してAppSyncのデータソースに書き込むという流れにすることにしました。

これは割とキックオフの直後ぐらいに決まっていました。
新しい技術に投資しておきたかった
こう書くとものすごく考えて採用したように見えますが、要はやってみたかったというのが大きいです。 既存のプロダクト同様APIサーバーをgoで書いて、クローラーをpythonやgoで書いていればサーバーサイドはもっと早く準備できていた可能性はあります。 ただやはり、既存の構成の使い回しだけでは知見を貯められないので新規でアプリを作るこのタイミングで色々なことに挑戦しておきたいという思いがありました。
実際のアーキテクチャ

こちらが実際のサーバーサイドの構成図です。
- クローラーがメディアのフィードをパースしてDynamoDBやS3に書き込み
- クローラーのDynamoDBからStreamでPreprocessor(Step Functions)が起動
- Step Functions内で記事の分類やタグ付けを行う
- 分類結果をElasticsearch ServiceやDynamoDBに書き込み
という流れになってます。クロールするスケジュールはCloud Watch Eventで定義してSQSにキューイングしてからlambdaを起動しています。
Step Functionsについて
AWS Step Functionsは2016年12月にリリースされたサービスでそこまで新しいものではありませんが、Gunosy社内での利用実績はありませんでした。
Step Functionsを使うと複数のlambdaを組み合わせて1つのワークフローを定義することができます。
DynamoDB ストリームとlambdaをつなげても同様のことが可能ですが、フローが複雑だと処理の途中で失敗した場合にどこで失敗したのかを調査したり、再実行するのが難しくなってきます。
Step Functionsは1つのステートマシン毎に1000実行まで履歴を保持してくれます。また、ステートマシンの入出力だけでなく、各タスクの入出力も記録してくれます。 これがあるだけでも1つのlambdaをStep Functionsでラップしたくなります。
グノスポではメディアからクロールした記事を形態素解析して、カテゴリ分類して、タグ付けするというのをStep Functionsを使って定義しています(図の右下部)。
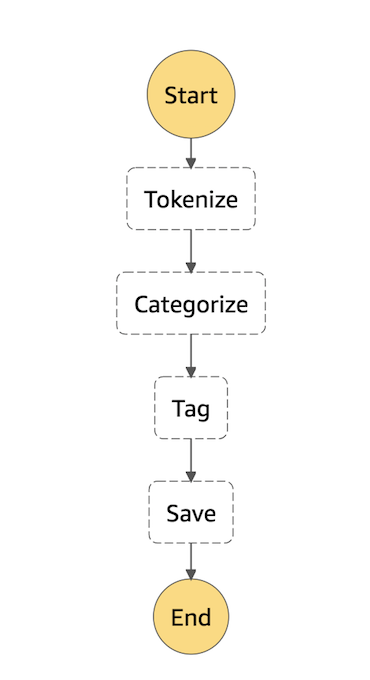
{ "Comment": "preprocessor", "StartAt": "Tokenize", "States": { "Tokenize": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:article-prep_tokenize-article", "InputPath": "$", "ResultPath": "$.tokenizerResult", "Next": "Categorize", "Retry": [ { "ErrorEquals": ["States.TaskFailed"], "IntervalSeconds": 10, "MaxAttempts": 3, "BackoffRate": 2 } ] }, "Categorize": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:article-prep_categorize-article", "InputPath": "$", "ResultPath": "$.classifierResult", "Next": "Tag", "Retry": [ { "ErrorEquals": ["States.TaskFailed"], "IntervalSeconds": 10, "MaxAttempts": 3, "BackoffRate": 2 } ] }, "Tag": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:article-prep_tag-article", "InputPath": "$", "ResultPath": "$.taggerResult", "Next": "Save", "Retry": [ { "ErrorEquals": ["States.TaskFailed"], "IntervalSeconds": 10, "MaxAttempts": 3, "BackoffRate": 2 } ] }, "Save": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:article-prep_save-article", "InputPath": "$", "ResultPath": "$.saveResult", "End": true } } }
今回はシーケンシャルにlambdaを実行しているだけですが、DynamoDB ストリームとlambdaだけでは難しい複数の処理を並列に実行するといったこともStep Functionsを使えば可能になります。
jsonでワークフローを定義するのはなれるまで厳しいものがありますが、使いこなせると強力なサービスだと思います。
サーバーサイドkotlinについて
最近では目新しさもないかもしれませんが、グノスポのサーバーサイドはlambdaもECSのタスクも全てkotlinで書かれています。 これは、
- AppSyncのSDKが
Java,swift,JavaScriptしかない → goが使えない - グノシーライブの開発でサーバーサイドkotlinの実績を積んでいた
- aws-sdk-javaやその他Javaのライブラリの充実
といった理由が大きかったです。
所感
良かった点
- 1つのlambdaがシンプルになってレビューしやすい
- lambdaをモノリスリポジトリにしたのでモジュールの共有が簡単
- 現在30弱のlambdaがいる
- 簡単にスケールアップできる
- lambdaの並行実行数、DynamoDBのキャパシティ(※上限緩和申請は必要)
- 複数言語開発によるコンテキストスイッチがない
課題
- こなれるまで開発速度が出ない
- 一気に新しいことやり過ぎた感(途中なんどやめようと思ったか...)
- Step Functionsが高い
- これは完全に調査不足なんですが、Step Functionsをlambdaと同じ感覚で多用すると結構な金額になります。もう少しお安くなると良いんですが。。。
- 今後無駄にStep Functionsを実行している箇所を減らしていく予定です。
- サーバーサイドのkotlin(Java) AppSync clientがないので独自で作る必要があった
- ベースはandroid版のsdk(実態はawsの認証 + apollo)
- github.com
- pure kotlinなserverside AppSync SDKがほしい。。
- JVM lambdaのコールドスタート
- GraalVMでネイティブイメージ作ろうとしたがClassloaderを使っているため挫折
- engineering.opsgenie.com
- 先行投資しすぎたため本来はRDBで管理したかったデータもDynamoに入ってる
- → 今後リファクタ
おわりに
今回はグノスポのサーバーサイドのアーキテクチャについて紹介しました。 AppSyncは比較的新しいサービスなので本番環境での導入事例がまだ少ない状況だと思います。 今回紹介した内容が少しでもAppSync + サーバーレスでサービスを作る参考になれば幸いです。
今後もグノスポをよろしくお願い致します!
また、グノシーでは一緒にグノスポをグロースさせてくれる仲間を募集しています!興味のある方は是非ご応募ください!