広告技術部のUT@mocyutoです
Gunosyではニュース記事を配信運用するメディア部門とアプリ上などに広告を配信運用する広告部門があります。 (本記事では「メディア」とはグノシーやニュースパスなどのサービスを指し、「広告」はそのメディアに出す広告を指します。) 今回は広告部門が運用している広告システムのスケールの仕組みについて紹介します。
課題
メディア側のシステムは各サービスごとにチームが分かれており、それぞれ別のシステムで稼働しています。
しかし、広告側のシステムは単一のシステムで動いており、各メディアの広告配信すべてを担っています。
そのため、サービスが増えるごとにトラフィックが増える仕様になっています。
特に速報などのプッシュ通知をメディアが送信すると一気にユーザはアプリを開くため、急激なスパイクが発生します。
そのスパイクは通常時の10倍以上のトラフィックが発生します。
以下datadogのrequestグラフです。
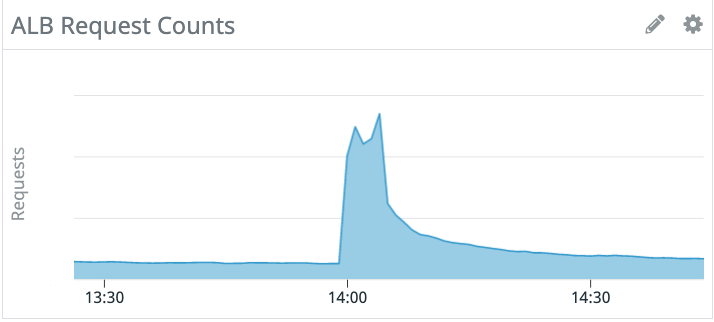
このスパイクを受けるためにはもちろんサーバを増やす必要がありますが、単純なオートスケーリングでは間に合いません。 広告のシステムはkubernetesで稼働しているので、HPAとcluster autoscalerでpod数は管理されていますが、それらだけでこのスパイクは受け止められません。
解決策
この問題の解決策としてはプッシュ通知前にスケールさせることになるでしょう。 この速報のプッシュ通知はGunosyでは社内管理画面を通して人手で判断して送っています。 もちろんトラフィックが増えるのは各メディアも同じで、その管理画面からプッシュ通知の作成画面とメディアサービスのリソースを増やすボタンも用意されており、送信前にそのボタンを押すことでスケールさせていました。
広告システム側は今まではピーク帯で耐えられるようなリソースを常時確保しているという状況でしたが、各メディアで増やすタイミングで広告システムもスケールさせる仕組みを作成しました。
仕組み
スケーリングの仕組みとして、プッシュ通知によるトラフィック増加と特定時間帯のトラフィック増加があり、その両方に対して対応する必要があります。 そこで、以下の二系統のスケールする仕組みを作成します。
- スパイクスケーリング
- スケジュールスケーリング
スパイクスケーリング
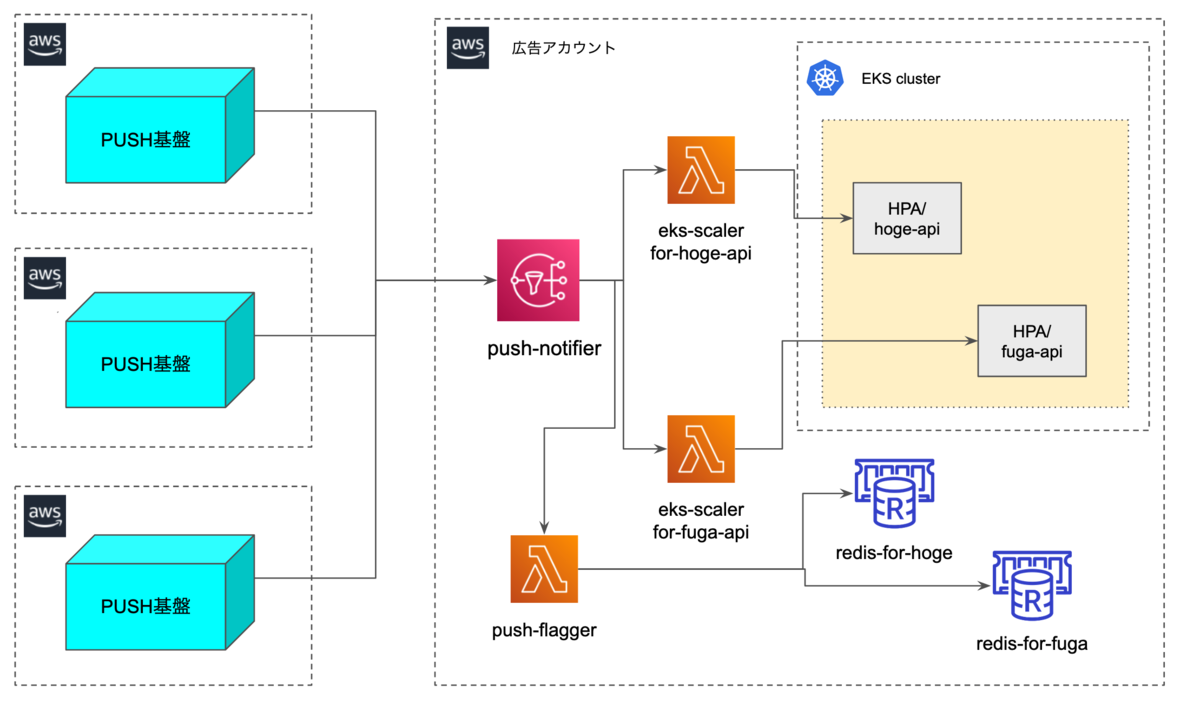
速報Pushを送信する際に各メディアのアカウントから広告アカウントのSNSに通知を送ります。 SQSなどのキューではなくSNSにしたのは、速報後すぐにスケールさせる即時性が必要だったからです。 SNSはeks-scalerという各API用のlambdaに対して通知を送り、そのlambdaは各APIのHPA(Horizontal Pod AutoScaler)に対して、minReplicaを変更します。
それとは別にSNSはpush-flaggerという速報が来たことを記録するlambdaにも通知を送ります。 このlambdaは各APIが持っているRedisへpush flagをセットします。 このフラグは数十分でexpireするようにしています。 なぜフラグをセットするのかはスケジュールスケーリングとの兼ね合いなので次の項で説明します。
スケジュールスケーリング
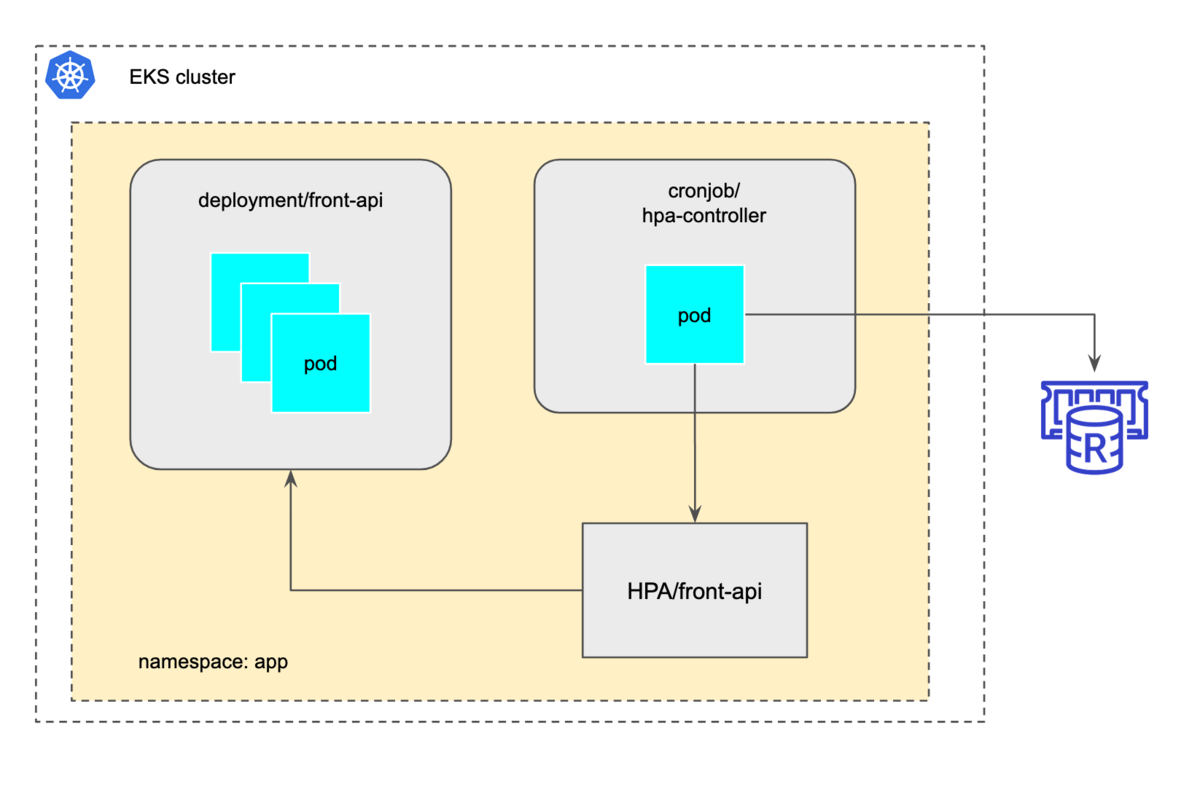
こちらは単純で10分おきに稼働するk8s内のcronjobで直接hpaのminReplicaを変更させています。
ただ単純にminReplicaを変更していると、速報が来ているのにminReplicaを変更してしまいます。 そこで、速報時に格納したpush flaggerのフラグをチェックし、あればこのスケジュールスケーリングは実行しないようにしています。 速報のフラグはexpireを設定しているので自動で消えるので、速報発生時だけを気にしていればよい仕組みになっています。
スケールのロジックを記述
こちらはどのような言語を利用してもよいのですが、弊社ではスパイクスケーリングのLambdaはGoで記述しており、スケジュールスケーリングはRubyのsystemメソッドから直接kubectlを叩かせています。
Goの場合は以下のクライアントがあるのでそれを利用すると良いかなと思います。 github.com
kubectlを直接叩く場合は、特に言語に依存はしないのでチームに合った言語を利用するとよいでしょう。
また、kubectlやkubernetes クライアントを使う場合、RBACでk8s内での権限を付与してあげる必要があるので、忘れずに設定しましょう。
RoleもしくはClusterRoleのHPAを編集する権限が最低限必要です。 以下はClusterRoleとしての例です。
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: hpa-controller # 動かすpodの名前 rules: - apiGroups: ["autoscaling"] resources: ["horizontalpodautoscalers"] # アクセスするHPAを指定 verbs: ["get", "patch", "update"]
まとめ
すべてのアクセス集中をAutoScalingのみで捌くのは厳しいのでそれぞれのサービス特性に応じて、対策を立てる必要があります。 完全に5xxを無くすというのは、なかなか大変なので各社苦労されているのかなと思いますが、弊社の場合定期的なスパイクと速報が混ざるので、このようなスケーリングの仕組みを作っています。
また、現状各APIがredisを持っていたのでそれぞれのRedisに投げ込んでいますが、もし各APIがRedisなどデータストアを持っていなければ、この仕組みではアクセス頻度が少ないため、RedisよりdynamoDBのほうが安価に済むので各API横断の単一のdynamodbなどを別途立てることをおすすめします。