こんにちは、広告技術部のyamaYuです。 最近は『SPY×FAMILY』にハマっています。 めちゃめちゃ面白いです。 それとヨルさんの声優さんが好きです。
さて、先日 GunosyAds の管理画面をEKSに移行したのですが、Podのロールアウト時に5xxエラーが発生するという問題に当たりました。 その際にダウンタイムなしにPodをロールアウトするための設定について調べたので、この記事ではそのことについてまとめようと思います。
前提
まず前提の共有のために今回扱うシステムであるGunosyAdsの管理画面の構成を簡単に説明します。 このシステムはAWS EKS上のKubernetesクラスターに展開されたサービスの一つです。 AWS Load Balancer Controller 管理下のALBから IPターゲットタイプ でトラフィックをPodにルーティングしています。
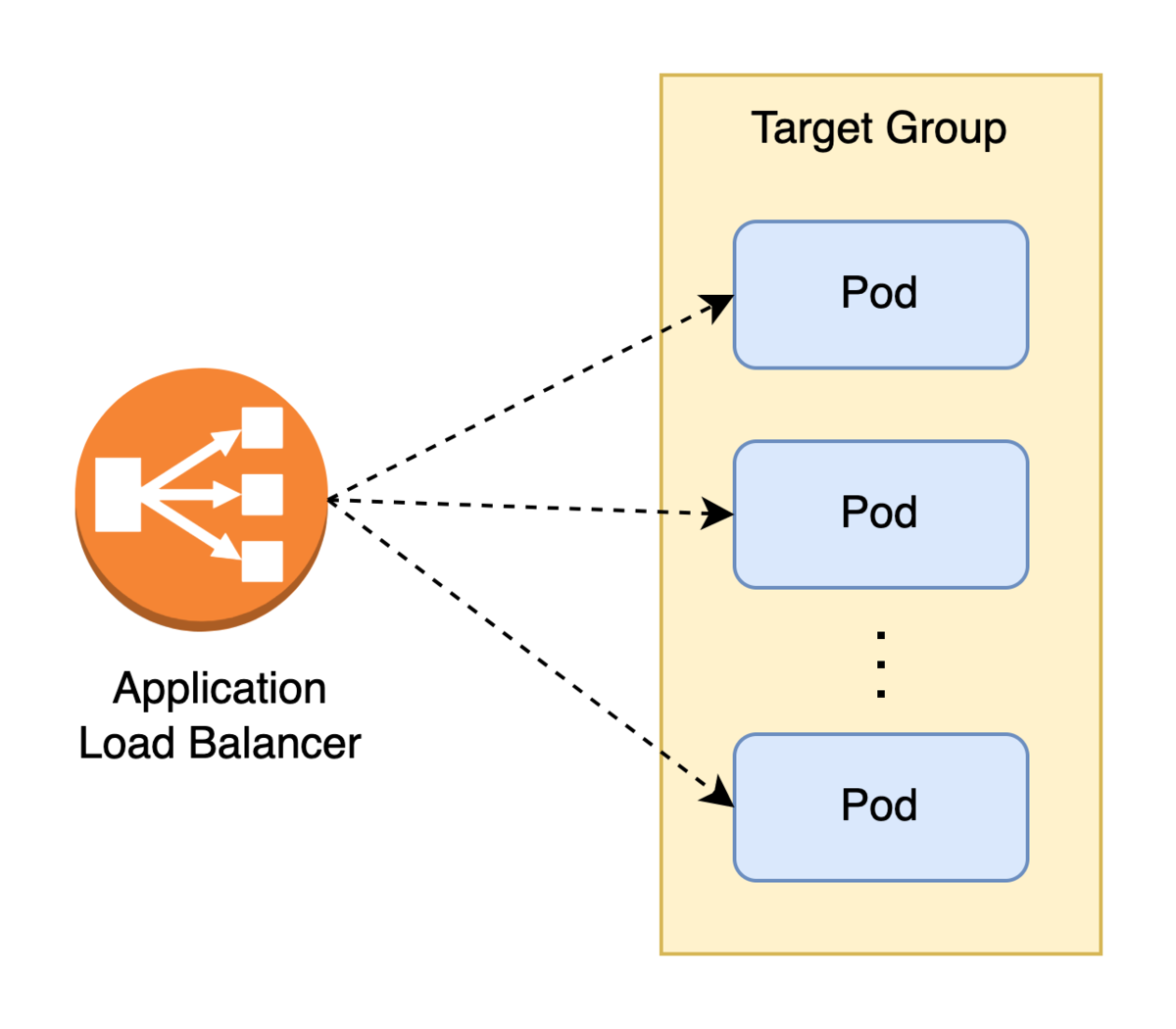
問題: Podのロールアウト時に5xxエラーが発生する
本番環境をEKSに切り替えてから様子をみていたところ、通常時には特に問題ないのですが、デプロイの度に数件の5xxエラーがターゲット側で発生していることがわかりました*1。 デプロイ時にはPodがロールアウトされるのですが、この時のPodとALBの挙動を理解していないと、(1)Pod削除時にシャットダウン中のPodにトラフィックをルーティングしてしまったり、(2)Pod作成時にアプリケーションの準備が整っていないPodにリクエストを流してしまったりする可能性があります。 発生していたエラーはこれらが原因でした。
解決策
(1) Pod削除時の5xx
Podの削除が始まると、ALBのターゲットグループのステータスがDrainingになり、新規トラフィックがPodにルーティングされなくなります。
Drainingは
登録解除の遅延
の時間 deregisration_delay.timeout_seconds だけ継続され、この間にPodが抱えているリクエストが処理されます。
その後Unusedになりターゲットグループから登録解除されます。
ここでポイントなのは、ターゲットグループのステータスの変化はアプリケーションの終了とは非同期である点です。
ターゲットグループのステータスがDrainingになる前にアプリケーションが終了してしまうと、トラフィックがPodに流れるもののレスポンスを返せず502エラーになります(図2上)。

この問題の解決策はアプリケーションのコンテナにpreStopで一定時間のsleepを設定することです。
Drainingになるまでアプリケーションの終了を遅延させられるためエラーを回避できます(図2下)。
sleepの秒数はターゲットグループのステータスがHealthyからDrainingなるのにかかる時間に加え、 システムが抱えているリクエストを処理するのに必要な時間を設定します。 今回のシステムには負荷の高い集計処理があるため、その処理時間を想定して30秒に設定しました。
apiVersion: apps/v1 kind: Deployment spec: spec: containers: - name: nginx lifecycle: preStop: exec: command: [ "/bin/sh", "-c", "sleep 30" ] ︙
また上記とは別の観点ですが、Podが抱えるリクエストの処理を完了する前にターゲットグループのステータスがUnusedになってしまうとエラーになります。 登録解除の遅延時間のデフォルトの値は300秒とかなり長めに設定されており、大方のケースでは問題にはならないと思われますが、設定を変える場合はリクエストの処理にかかる時間を考慮する必要があります。
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/target-group-attributes: deregistration_delay.timeout_seconds=30 ︙
(2) Pod作成時の5xx
Kubernetesのドキュメントの Pod conditions に書かれている通り、PodがReadyになるとトラフィックがルーティングされるようになります。 ここでPodがReadyとは下記の2つの条件が満たされる状態のことを意味します。
- Pod内のすべてのコンテナがReady
- 設定されたすべてのReadiness GateがTrue (デフォルトは設定なし)
なお「コンテナがReady」とはデフォルトでは単にコンテナが立ち上がっている状態のことを指します。
今回のシステムには、起動直後はリクエスト処理に時間がかかるという特性がありました。 そのためPodがReadyになりターゲットグループに登録されたものの、 一定時間は十分なリクエスト処理能力を発揮できていませんでした。 ALBによるヘルスチェックも行われますが、システムはヘルスチェックへの応答はできるが実際のトラフィックを受けるには処理能力が不十分という状態でした。
この問題への対応としてアプリケーションのコンテナに Probe を設定しました。 Probeはコンテナがリクエストへ応答する準備ができている事を保証するものです。 これがあるとkubeletによるヘルスチェックが通るまでコンテナがReadyにならなくなります。 これによりアプリケーションの起動処理が完了するまでPodがReadyになるのを遅延させることができます。
下記のようにstartupProbeとreadinessProbeを設定しました。
startupProbe の initialDelaySeconds でアプリケーションの起動を待つためにヘルスチェック開始を遅延させています。
failureThresholdはヘルスチェック失敗とみなすまでの試行回数です。
startupProbeでは起動を待つために試行回数を多めに設定し、
readinessProbeでは障害を早く検知できるように少なめに設定しています。
apiVersion: apps/v1 kind: Deployment spec: spec: containers: - name: nginx startupProbe: failureThreshold: 20 initialDelaySeconds: 5 httpGet: port: 80 path: /ping readinessProbe: failureThreshold: 3 # default value httpGet: port: 80 path: /ping ︙
先程述べたPodがReadyとなる条件一つであるReadiness Gateについても簡単に触れておきます。 こちらは前述したProbeよりも複雑な条件を設定するためのものです。 AWS Load Balancer ControllerはReadiness Gateに対応しており、ターゲットグループのステータスをPodに紐付けることができます。
稼働しているPodが少なく、アプリケーションの起動よりもターゲットグループへの登録にかかる時間が長いシステムでは、ロールアウト時に新しいPodがターゲットグループ上でHealthyになる前に古いPodが削除されることで、Healthyなターゲットが一時的に少なくなる/無くなる問題が起こりえます。 Readiness Gateを使うことでHealthyになるまでロールアウトの進行を待機させることができるため問題に対処できます。
今回のシステムではPodの稼働数がそれなりにあり、このような問題は発生しなかったためReadiness Gateは設定していません*2。
まとめ
今回の記事ではPodのロールアウト時に5xxエラーが発生する問題について、 Pod削除/生成時における問題と解決方法をまとめました。 Podのロールアウト時という一時的な問題ではありますが、デプロイの頻度や管理しているPodの数が多い場合にはエラーの数も増えてきます。 そもそも不必要なダウンタイムはないに越したことはありません。 この記事が少しでもご参考になれば幸いです。